16 Regressionsanalyse. Methoden der mathematischen Statistik
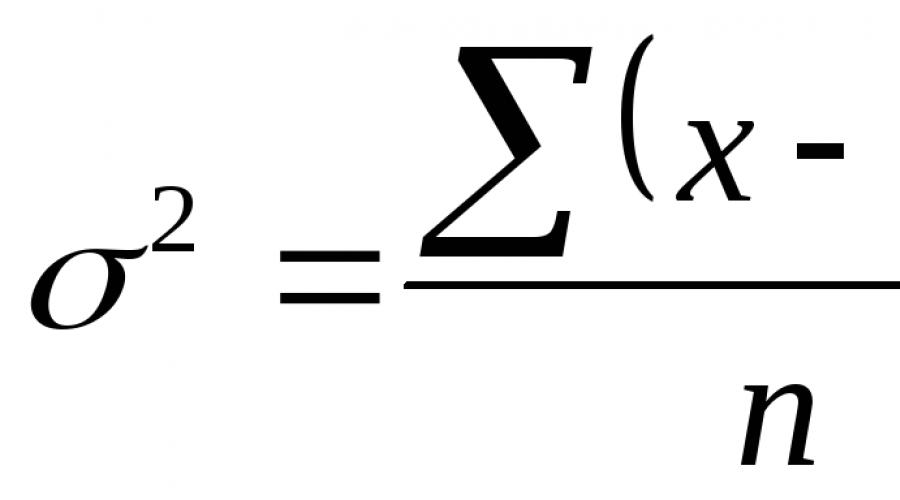
Die Regressionsanalyse untersucht die Abhängigkeit einer bestimmten Größe von einer anderen Größe oder mehreren anderen Größen. Die Regressionsanalyse wird hauptsächlich in mittelfristigen Prognosen sowie in langfristigen Prognosen eingesetzt. Mittel- und langfristige Zeiträume ermöglichen es, Veränderungen im Geschäftsumfeld zu erkennen und die Auswirkungen dieser Veränderungen auf den untersuchten Indikator zu berücksichtigen.
Um eine Regressionsanalyse durchzuführen, benötigen Sie:
Verfügbarkeit jährlicher Daten zu den untersuchten Indikatoren,
das Vorhandensein einmaliger Prognosen, d.h. solche Prognosen, die nicht mit dem Eintreffen neuer Daten korrigiert werden.
Regressionsanalysen werden in der Regel für Objekte durchgeführt, die komplexer, multifaktorieller Natur sind, wie z. B. Investitionsvolumen, Gewinn, Umsatzvolumen usw.
Bei normative Prognosemethode Es werden die Wege und Fristen zur Erreichung möglicher Zustände des als Ziel gesetzten Phänomens festgelegt. Es geht darum, das Erreichen gewünschter Zustände eines Phänomens auf der Grundlage vorgegebener Normen, Ideale, Anreize und Ziele vorherzusagen. Diese Prognose beantwortet die Frage: Auf welche Weise können Sie erreichen, was Sie wollen? Für Programm- oder Zielprognosen wird häufiger die normative Methode eingesetzt. Es werden sowohl der quantitative Ausdruck des Standards als auch eine bestimmte Leistungsskala der Bewertungsfunktion verwendet
Bei der Verwendung eines quantitativen Ausdrucks, beispielsweise physiologischer und rationaler Konsumnormen einzelner Lebensmittel und Non-Food-Produkte, die von Spezialisten für verschiedene Bevölkerungsgruppen entwickelt wurden, ist es möglich, das Konsumniveau dieser Güter zu bestimmen die Jahre vor dem Erreichen der angegebenen Norm. Solche Berechnungen nennt man Interpolation. Interpolation ist eine Methode zur Berechnung von Indikatoren, die in der dynamischen Reihe eines Phänomens fehlen, basierend auf einer etablierten Beziehung. Nimmt man den tatsächlichen Wert des Indikators und den Wert seiner Standards als Extremelemente der dynamischen Reihe, ist es möglich, die Werte der Werte innerhalb dieser Reihe zu bestimmen. Daher gilt die Interpolation als normative Methode. Die zuvor angegebene Formel (4), die bei der Extrapolation verwendet wurde, kann bei der Interpolation verwendet werden, wobei y nicht mehr die tatsächlichen Daten, sondern den Standardindikator charakterisiert.
Im Falle der Verwendung einer Skala (Feld, Spektrum) im normativen Verfahren weisen die Fähigkeiten der Bewertungsfunktion, also der Präferenzverteilungsfunktion, ungefähr die folgende Abstufung auf: unerwünscht – weniger wünschenswert – wünschenswerter – am wünschenswertesten – optimal ( Standard).
Die normative Prognosemethode hilft dabei, Empfehlungen zu entwickeln, um die Objektivität und damit die Wirksamkeit von Entscheidungen zu erhöhen.
Modellieren, vielleicht die komplexeste Prognosemethode. Unter mathematischer Modellierung versteht man die Beschreibung eines wirtschaftlichen Phänomens durch mathematische Formeln, Gleichungen und Ungleichungen. Der mathematische Apparat muss den prognostizierten Hintergrund genau widerspiegeln, obwohl es ziemlich schwierig ist, die gesamte Tiefe und Komplexität des prognostizierten Objekts vollständig abzubilden. Der Begriff „Modell“ leitet sich vom lateinischen Wort modelus ab, was „Maß“ bedeutet. Daher wäre es richtiger, die Modellierung nicht als Prognosemethode, sondern als Methode zur Untersuchung eines ähnlichen Phänomens mithilfe eines Modells zu betrachten.
Im weitesten Sinne sind Modelle Ersatzstoffe für den Untersuchungsgegenstand, die diesem so ähnlich sind, dass neue Erkenntnisse über den Gegenstand gewonnen werden können. Ein Modell sollte als mathematische Beschreibung eines Objekts betrachtet werden. In diesem Fall wird ein Modell als ein Phänomen (Objekt, Umgebung) definiert, das in gewisser Weise mit dem untersuchten Objekt korrespondiert und dieses im Forschungsprozess ersetzen kann, indem es Informationen über das Objekt präsentiert.
Bei einem engeren Verständnis des Modells wird es als Objekt der Vorhersage betrachtet; seine Untersuchung ermöglicht es, Informationen über die möglichen Zustände des Objekts in der Zukunft und Möglichkeiten zur Erreichung dieser Zustände zu erhalten. In diesem Fall besteht das Ziel des Vorhersagemodells darin, Informationen nicht über das Objekt im Allgemeinen, sondern nur über seine zukünftigen Zustände zu erhalten. Beim Erstellen eines Modells kann es dann möglicherweise unmöglich sein, seine Übereinstimmung mit dem Objekt direkt zu überprüfen, da das Modell nur seinen zukünftigen Zustand darstellt und das Objekt selbst derzeit möglicherweise nicht vorhanden ist oder eine andere Existenz hat.
Modelle können materiell oder ideal sein.
Die Wirtschaftswissenschaften verwenden ideale Modelle. Das fortschrittlichste Idealmodell zur quantitativen Beschreibung eines sozioökonomischen (ökonomischen) Phänomens ist ein mathematisches Modell unter Verwendung von Zahlen, Formeln, Gleichungen, Algorithmen oder grafischer Darstellung. Mithilfe ökonomischer Modelle ermitteln sie:
Abhängigkeit zwischen verschiedenen Wirtschaftsindikatoren;
verschiedene Arten von Beschränkungen für Indikatoren;
Kriterien zur Optimierung des Prozesses.
Eine aussagekräftige Beschreibung eines Objekts kann in Form seines formalisierten Diagramms dargestellt werden, das angibt, welche Parameter und Ausgangsinformationen gesammelt werden müssen, um die erforderlichen Mengen zu berechnen. Ein mathematisches Modell enthält im Gegensatz zu einem formalisierten Schema spezifische numerische Daten, die das Objekt charakterisieren. Die Entwicklung eines mathematischen Modells hängt weitgehend vom Verständnis des Prognostikers für das Wesen des modellierten Prozesses ab. Basierend auf seinen Ideen stellt er eine Arbeitshypothese auf, mit deren Hilfe eine analytische Aufzeichnung des Modells in Form von Formeln, Gleichungen und Ungleichungen erstellt wird. Durch die Lösung des Gleichungssystems erhält man spezifische Parameter der Funktion, die die zeitliche Änderung der gewünschten Variablen beschreiben.
Die Reihenfolge und Reihenfolge der Arbeiten als Element der Prognoseorganisation wird abhängig von der verwendeten Prognosemethode bestimmt. Typischerweise wird diese Arbeit in mehreren Schritten durchgeführt.
Stufe 1 – prädiktive Retrospektion, d. h. Festlegung des Prognoseobjekts und des Prognosehintergrunds. Die Arbeiten in der ersten Phase werden in der folgenden Reihenfolge ausgeführt:
Erstellung einer Beschreibung eines Objekts in der Vergangenheit, die eine vorab prognostizierte Analyse des Objekts, Bewertung seiner Parameter, ihrer Bedeutung und gegenseitigen Beziehungen umfasst,
Identifizierung und Bewertung von Informationsquellen, Ablauf und Organisation der Arbeit mit ihnen, Sammlung und Platzierung retrospektiver Informationen;
Festlegung von Forschungszielen.
Im Rahmen der Aufgaben der Prognoserückschau untersuchen Prognostiker die Entwicklungsgeschichte des Objekts und den Prognosehintergrund, um eine systematische Beschreibung dieser zu erhalten.
Stufe 2 – prädiktive Diagnose, bei der eine systematische Beschreibung des Prognoseobjekts und Prognosehintergrunds untersucht wird, um Trends in deren Entwicklung zu erkennen und Modelle und Prognosemethoden auszuwählen. Die Arbeiten werden in der folgenden Reihenfolge ausgeführt:
Entwicklung eines Modells des Prognoseobjekts, einschließlich einer formalisierten Beschreibung des Objekts, Überprüfung des Grades der Angemessenheit des Modells an das Objekt;
Auswahl von Prognosemethoden (Haupt- und Hilfsmethoden), Entwicklung von Algorithmen und Arbeitsprogrammen.
Stufe 3 – Schutz, d. h. der Prozess der umfassenden Entwicklung der Prognose, einschließlich: 1) Berechnung der vorhergesagten Parameter für einen bestimmten Vorlaufzeitraum; 2) Synthese einzelner Komponenten der Prognose.
Stufe 4 – Bewertung der Prognose, einschließlich ihrer Überprüfung, d. h. Bestimmung des Grades der Zuverlässigkeit, Genauigkeit und Gültigkeit.
Im Zuge der Prospektion und Bewertung werden auf Basis der vorangegangenen Stufen die Probleme der Prognose und deren Bewertung gelöst.
Die angegebenen Stufen sind Näherungswerte und hängen von der Hauptprognosemethode ab.
Die Prognoseergebnisse werden in Form eines Zertifikats, Berichts oder anderen Materials erstellt und dem Kunden vorgelegt.
Bei der Prognose kann der Betrag der Abweichung der Prognose vom tatsächlichen Zustand des Objekts angegeben werden, der als Prognosefehler bezeichnet wird und nach folgender Formel berechnet wird:
;
 ;
; .
(9.3)
.
(9.3)
Fehlerquellen bei Prognosen
Die Hauptquellen können sein:
1. Einfache Übertragung (Extrapolation) von Daten aus der Vergangenheit in die Zukunft (das Unternehmen hat beispielsweise keine anderen Prognosemöglichkeiten als 10 % Umsatzwachstum).
2. Die Unfähigkeit, die Wahrscheinlichkeit eines Ereignisses und seine Auswirkungen auf das untersuchte Objekt genau zu bestimmen.
3. Unvorhergesehene Schwierigkeiten (störende Ereignisse), die die Umsetzung des Plans beeinträchtigen, beispielsweise die plötzliche Entlassung des Leiters der Vertriebsabteilung.
Im Allgemeinen nimmt die Prognosegenauigkeit zu, wenn Prognoseerfahrung gesammelt und die Methoden verfeinert werden.
Die Regressionsanalyse ist eine Methode zur Modellierung gemessener Daten und zur Untersuchung ihrer Eigenschaften. Die Daten bestehen aus Wertepaaren der abhängigen Variablen (Antwortvariable) und der unabhängigen Variablen (erklärende Variable). Ein Regressionsmodell ist eine Funktion der unabhängigen Variablen und Parameter mit einer hinzugefügten Zufallsvariablen.
Korrelationsanalyse und Regressionsanalyse sind verwandte Abschnitte mathematische Statistik, und dienen dazu, die statistische Abhängigkeit einer Reihe von Größen anhand von Stichprobendaten zu untersuchen; einige davon sind zufällig. Bei der statistischen Abhängigkeit stehen die Größen nicht in einem funktionalen Zusammenhang, sondern werden durch eine gemeinsame Wahrscheinlichkeitsverteilung als Zufallsvariablen definiert.
Suchtforschung zufällige Variablen führt zu Regressionsmodellen und Regressionsanalysen basierend auf Beispieldaten. Wahrscheinlichkeitstheorie und mathematische Statistik stellen lediglich ein Instrument zur Untersuchung statistischer Abhängigkeiten dar, zielen jedoch nicht darauf ab, einen Kausalzusammenhang herzustellen. Ideen und Hypothesen über einen Kausalzusammenhang müssen aus einer anderen Theorie stammen, die eine sinnvolle Erklärung des untersuchten Phänomens ermöglicht.
Numerische Daten stehen in der Regel in expliziten (bekannten) oder impliziten (verborgenen) Beziehungen zueinander.
Die Indikatoren, die durch direkte Berechnungsmethoden gewonnen werden, d. h. nach bisher bekannten Formeln berechnet werden, stehen in einem klaren Zusammenhang. Zum Beispiel Prozentsatz der Planerfüllung, Ebenen, spezifisches Gewicht, Betragsabweichungen, prozentuale Abweichungen, Wachstumsraten, Wachstumsraten, Indizes usw.
Verbindungen der zweiten Art (implizit) sind im Vorhinein unbekannt. Um komplexe Phänomene bewältigen zu können, ist es jedoch notwendig, komplexe Phänomene erklären und vorhersagen zu können. Deshalb streben Spezialisten mit Hilfe von Beobachtungen danach, verborgene Abhängigkeiten zu erkennen und in Formeln auszudrücken, also Phänomene oder Prozesse mathematisch zu modellieren. Eine solche Möglichkeit bietet die Korrelations-Regressionsanalyse.
Mathematische Modelle werden für drei allgemeine Zwecke erstellt und verwendet:
- * zur Erläuterung;
- * zur Vorhersage;
- * Zum Fahren.
Mit den Methoden der Korrelations- und Regressionsanalyse messen Analysten die Nähe der Zusammenhänge zwischen Indikatoren anhand des Korrelationskoeffizienten. Dabei werden Verbindungen unterschiedlicher Stärke (stark, schwach, mäßig usw.) und unterschiedlicher Richtung (direkt, umgekehrt) entdeckt. Sollten sich die Zusammenhänge als signifikant herausstellen, wäre es ratsam, ihren mathematischen Ausdruck in Form eines Regressionsmodells zu finden und die statistische Signifikanz des Modells zu bewerten.
Die Regressionsanalyse wird als die wichtigste Methode der modernen mathematischen Statistik zur Identifizierung impliziter und verschleierter Zusammenhänge zwischen Beobachtungsdaten bezeichnet.
Die Problemstellung der Regressionsanalyse wird wie folgt formuliert.
Es gibt eine Reihe von Beobachtungsergebnissen. In diesem Satz entspricht eine Spalte einem Indikator, für den eine funktionale Beziehung zu den Parametern des Objekts und der Umgebung hergestellt werden muss, die durch die übrigen Spalten dargestellt werden. Erforderlich: Stellen Sie einen quantitativen Zusammenhang zwischen dem Indikator und den Faktoren her. Unter dem Problem der Regressionsanalyse wird in diesem Fall die Aufgabe verstanden, eine solche funktionale Abhängigkeit y = f (x2, x3, ..., xт) zu identifizieren, die die verfügbaren experimentellen Daten am besten beschreibt.
Annahmen:
die Anzahl der Beobachtungen reicht aus, um statistische Muster hinsichtlich Faktoren und ihrer Beziehungen aufzuzeigen;
die verarbeiteten Daten enthalten einige Fehler (Rauschen) aufgrund von Messfehlern und dem Einfluss nicht berücksichtigter Zufallsfaktoren;
Die Beobachtungsergebnismatrix ist die einzige Information über das Untersuchungsobjekt, die vor Beginn der Untersuchung verfügbar ist.
Die Funktion f (x2, x3, ..., xт), die die Abhängigkeit des Indikators von den Parametern beschreibt, wird als Regressionsgleichung (Funktion) bezeichnet. Der Begriff „Regression“ (Regression (lateinisch) – Rückzug, Rückkehr zu etwas) ist mit den Besonderheiten eines der spezifischen Probleme verbunden, die in der Phase der Methodenbildung gelöst werden.
Es empfiehlt sich, die Lösung des Problems der Regressionsanalyse in mehrere Phasen aufzuteilen:
Datenvorverarbeitung;
Auswahl der Art der Regressionsgleichungen;
Berechnung der Koeffizienten der Regressionsgleichung;
Überprüfen der Angemessenheit der konstruierten Funktion an die Beobachtungsergebnisse.
Die Vorverarbeitung umfasst die Standardisierung der Datenmatrix, die Berechnung von Korrelationskoeffizienten, die Überprüfung ihrer Signifikanz und den Ausschluss unbedeutender Parameter aus der Berücksichtigung.
Auswahl des Typs der Regressionsgleichung Die Aufgabe, die funktionale Beziehung zu bestimmen, die die Daten am besten beschreibt, erfordert die Überwindung einer Reihe grundlegender Schwierigkeiten. Im Allgemeinen kann für standardisierte Daten die funktionale Abhängigkeit des Indikators von den Parametern wie folgt dargestellt werden:
y = f (x1, x2, …, xm) + e
wobei f eine bisher unbekannte zu bestimmende Funktion ist;
e – Datennäherungsfehler.
Diese Gleichung wird üblicherweise als Stichprobenregressionsgleichung bezeichnet. Diese Gleichung charakterisiert die Beziehung zwischen der Variation des Indikators und den Variationen der Faktoren. Und das Korrelationsmaß misst den Anteil der Variation eines Indikators, der mit der Variation der Faktoren verbunden ist. Mit anderen Worten: Die Korrelation zwischen einem Indikator und Faktoren kann nicht als Zusammenhang zwischen ihren Niveaus interpretiert werden, und die Regressionsanalyse erklärt nicht die Rolle von Faktoren bei der Erstellung eines Indikators.
Ein weiteres Merkmal betrifft die Bewertung des Einflussgrades jedes Faktors auf den Indikator. Die Regressionsgleichung liefert keine Bewertung des einzelnen Einflusses jedes Faktors auf den Indikator; eine solche Bewertung ist nur möglich, wenn alle anderen Faktoren nicht mit dem untersuchten Faktor zusammenhängen. Wenn der untersuchte Faktor mit anderen Faktoren zusammenhängt, die den Indikator beeinflussen, erhält man ein gemischtes Merkmal des Einflusses des Faktors. Dieses Merkmal beinhaltet sowohl den direkten Einfluss des Faktors als auch den indirekten Einfluss, der durch die Verbindung mit anderen Faktoren und deren Einfluss auf den Indikator ausgeübt wird.
Es wird nicht empfohlen, Faktoren in die Regressionsgleichung einzubeziehen, die einen schwachen Zusammenhang mit dem Indikator, aber einen engen Zusammenhang mit anderen Faktoren haben. Faktoren, die funktional miteinander in Zusammenhang stehen, gehen nicht in die Gleichung ein (für sie beträgt der Korrelationskoeffizient 1). Die Einbeziehung solcher Faktoren führt zur Degeneration des Gleichungssystems zur Schätzung der Regressionskoeffizienten und zur Unsicherheit der Lösung.
Die Funktion f muss so gewählt werden, dass der Fehler e gewissermaßen minimal ist. Um einen funktionalen Zusammenhang auszuwählen, wird vorab eine Hypothese aufgestellt, zu welcher Klasse die Funktion f gehören könnte, und anschließend die „beste“ Funktion dieser Klasse ausgewählt. Die ausgewählte Funktionsklasse muss eine gewisse „Glattheit“ aufweisen, d. h. „Kleine“ Änderungen der Argumentwerte sollten „kleine“ Änderungen der Funktionswerte verursachen.
Ein in der Praxis weit verbreiteter Sonderfall ist eine polynomische oder lineare Regressionsgleichung ersten Grades
Zur Auswahl der Art der funktionalen Abhängigkeit kann folgende Vorgehensweise empfohlen werden:
Punkte mit Indikatorwerten werden im Parameterraum grafisch dargestellt. Bei einer großen Anzahl von Parametern ist es möglich, für jeden von ihnen Punkte zu konstruieren und so zweidimensionale Werteverteilungen zu erhalten;
basierend auf der Lage der Punkte und basierend auf einer Analyse des Wesens der Beziehung zwischen dem Indikator und den Parametern des Objekts wird eine Schlussfolgerung über die ungefähre Art der Regression oder ihre möglichen Optionen gezogen;
Nach der Berechnung der Parameter wird die Qualität der Näherung beurteilt, d.h. den Grad der Ähnlichkeit zwischen berechneten und tatsächlichen Werten bewerten;
Wenn die berechneten und tatsächlichen Werte im gesamten Aufgabenbereich nahe beieinander liegen, kann das Problem der Regressionsanalyse als gelöst angesehen werden. Andernfalls können Sie versuchen, einen anderen Polynomtyp oder eine andere analytische Funktion zu wählen, beispielsweise eine periodische.
Berechnen der Regressionsgleichungskoeffizienten
Es ist unmöglich, ein Gleichungssystem anhand der verfügbaren Daten eindeutig zu lösen, da die Anzahl der Unbekannten immer größer ist als die Anzahl der Gleichungen. Um dieses Problem zu lösen, sind zusätzliche Annahmen erforderlich. Gesunder Menschenverstand schlägt vor: Es ist ratsam, die Koeffizienten des Polynoms so zu wählen, dass ein minimaler Fehler bei der Datennäherung gewährleistet ist. Zur Bewertung von Approximationsfehlern können verschiedene Maßnahmen herangezogen werden. Als Maß dafür wird häufig der quadratische Mittelfehler verwendet. Auf dieser Grundlage wurde eine spezielle Methode zur Schätzung der Koeffizienten von Regressionsgleichungen entwickelt – die Methode der kleinsten Quadrate (LSM). Mit dieser Methode können Sie Maximum-Likelihood-Schätzungen der unbekannten Koeffizienten der Regressionsgleichung unter der Normalverteilungsoption erhalten, sie kann jedoch auch für jede andere Verteilung von Faktoren verwendet werden.
Das MNC basiert auf folgenden Bestimmungen:
die Werte der Fehler und Faktoren sind unabhängig und daher unkorreliert, d.h. Es wird davon ausgegangen, dass die Mechanismen zur Erzeugung von Interferenzen nicht mit dem Mechanismus zur Erzeugung von Faktorwerten zusammenhängen.
die mathematische Erwartung des Fehlers e muss gleich Null sein (die konstante Komponente ist im Koeffizienten a0 enthalten), mit anderen Worten, der Fehler ist eine zentrierte Größe;
Die Stichprobenschätzung der Fehlervarianz sollte minimal sein.
Wenn das lineare Modell ungenau ist oder die Parameter ungenau gemessen werden, können wir in diesem Fall mit der Methode der kleinsten Quadrate solche Werte der Koeffizienten finden, bei denen das lineare Modell das reale Objekt im Sinne der gewählten Standardabweichung am besten beschreibt Kriterium.
Die Qualität der resultierenden Regressionsgleichung wird durch den Grad der Nähe zwischen den Ergebnissen der Beobachtungen des Indikators und den durch die Regressionsgleichung in vorhergesagten Werten beurteilt vergebene Punkte Parameterraum. Liegen die Ergebnisse nahe beieinander, kann das Problem der Regressionsanalyse als gelöst betrachtet werden. Andernfalls sollten Sie die Regressionsgleichung ändern und die Berechnungen wiederholen, um die Parameter abzuschätzen.
Bei mehreren Indikatoren wird das Problem der Regressionsanalyse für jeden von ihnen unabhängig gelöst.
Bei der Analyse des Wesens der Regressionsgleichung sollten die folgenden Punkte beachtet werden. Der betrachtete Ansatz sieht keine separate (unabhängige) Bewertung von Koeffizienten vor – eine Änderung des Wertes eines Koeffizienten führt zu einer Änderung der Werte anderer. Die erhaltenen Koeffizienten sollten nicht als Beitrag des entsprechenden Parameters zum Wert des Indikators betrachtet werden. Eine Regressionsgleichung ist lediglich eine gute analytische Beschreibung der verfügbaren Daten und kein Gesetz, das die Beziehung zwischen Parametern und einem Indikator beschreibt. Diese Gleichung wird verwendet, um die Werte des Indikators in einem bestimmten Bereich von Parameteränderungen zu berechnen. Für Berechnungen außerhalb dieses Bereichs ist es nur bedingt geeignet, d. h. Es kann zur Lösung von Interpolationsproblemen und in begrenztem Umfang zur Extrapolation verwendet werden.
Der Hauptgrund für die Ungenauigkeit der Prognose liegt weniger in der Unsicherheit der Extrapolation der Regressionsgeraden als vielmehr in der erheblichen Variation des Indikators aufgrund von Faktoren, die im Modell nicht berücksichtigt wurden. Die Einschränkung der Prognosefähigkeit ist die Bedingung der Stabilität der im Modell nicht berücksichtigten Parameter und die Art des Einflusses der berücksichtigten Modellfaktoren. Wenn es sich abrupt ändert Außenumgebung, dann verliert die kompilierte Regressionsgleichung ihre Bedeutung.
Die Prognose, die durch Einsetzen des erwarteten Werts des Parameters in die Regressionsgleichung erhalten wird, ist eine Punkt-Eins-Prognose. Die Wahrscheinlichkeit, dass eine solche Prognose eintrifft, ist vernachlässigbar. Es empfiehlt sich, das Konfidenzintervall der Prognose zu bestimmen. Für einzelne Werte des Indikators sollte das Intervall Fehler in der Position der Regressionsgeraden und Abweichungen einzelner Werte von dieser Linie berücksichtigen.
FAZIT DER ERGEBNISSE
| Regressionsstatistik | |
| Plural R | 0,998364 |
| R Quadrat | 0,99673 |
| Normalisiertes R-Quadrat | 0,996321 |
| Standart Fehler | 0,42405 |
| Beobachtungen | 10 |
Schauen wir uns zunächst den oberen Teil der Berechnungen an, dargestellt in Tabelle 8.3a – Regressionsstatistiken.
Der Wert R-Quadrat, auch Maß für Sicherheit genannt, charakterisiert die Qualität der resultierenden Regressionsgeraden. Diese Qualität wird durch den Grad der Übereinstimmung zwischen den Quelldaten und dem Regressionsmodell (berechnete Daten) ausgedrückt. Das Maß der Sicherheit liegt immer innerhalb des Intervalls.
In den meisten Fällen liegt der R-Quadrat-Wert zwischen diesen Werten, die als Extremwerte bezeichnet werden, d. h. zwischen null und eins.
Wenn der R-Quadrat-Wert nahe bei eins liegt, bedeutet dies, dass das erstellte Modell fast die gesamte Variabilität der relevanten Variablen erklärt. Umgekehrt bedeutet ein R-Quadrat-Wert nahe Null, dass die Qualität des erstellten Modells schlecht ist.
In unserem Beispiel beträgt das Maß für die Sicherheit 0,99673, was auf eine sehr gute Anpassung der Regressionslinie an die Originaldaten hinweist.
Plural R- multipler Korrelationskoeffizient R - drückt den Grad der Abhängigkeit der unabhängigen Variablen (X) und der abhängigen Variablen (Y) aus.
Vielfaches R ist gleich Quadratwurzel Aus dem Bestimmtheitsmaß nimmt diese Größe Werte im Bereich von Null bis Eins an.
In der einfachen linearen Regressionsanalyse ist das Vielfache von R gleich dem Pearson-Korrelationskoeffizienten. Tatsächlich ist das Vielfache R in unserem Fall gleich dem Pearson-Korrelationskoeffizienten aus dem vorherigen Beispiel (0,998364).
| Chancen | Standart Fehler | t-Statistik | |
| Y-Kreuzung | 2,694545455 | 0,33176878 | 8,121757129 |
| Variable X 1 | 2,305454545 | 0,04668634 | 49,38177965 |
| * Eine gekürzte Version der Berechnungen wird bereitgestellt | |||
Betrachten Sie nun den mittleren Teil der Berechnungen, dargestellt in Tabelle 8.3b. Hier sind der Regressionskoeffizient b (2,305454545) und die Verschiebung entlang der Ordinatenachse angegeben, d.h. Konstante a (2,694545455).
Basierend auf den Berechnungen können wir die Regressionsgleichung wie folgt schreiben:
Y= x*2,305454545+2,694545455
Die Richtung der Beziehung zwischen Variablen wird anhand der Vorzeichen (negativ oder positiv) bestimmt. Regressionskoeffizienten(Koeffizient b).
Wenn das Schild an Regressionskoeffizienten- positiv, die Beziehung zwischen der abhängigen Variablen und der unabhängigen Variablen ist positiv. In unserem Fall ist das Vorzeichen des Regressionskoeffizienten positiv, daher ist auch die Beziehung positiv.
Wenn das Schild an Regressionskoeffizienten- negativ, die Beziehung zwischen der abhängigen Variablen und der unabhängigen Variablen ist negativ (invers).
In Tabelle 8.3c. Die Ergebnisse der Ableitung der Residuen werden vorgestellt. Damit diese Ergebnisse im Bericht erscheinen, müssen Sie beim Ausführen des Tools „Regression“ die Checkbox „Residuen“ aktivieren.
RÜCKZUG DES RESTES
| Überwachung | Vorhergesagtes Y | Reste | Standardwaagen |
|---|---|---|---|
| 1 | 9,610909091 | -0,610909091 | -1,528044662 |
| 2 | 7,305454545 | -0,305454545 | -0,764022331 |
| 3 | 11,91636364 | 0,083636364 | 0,209196591 |
| 4 | 14,22181818 | 0,778181818 | 1,946437843 |
| 5 | 16,52727273 | 0,472727273 | 1,182415512 |
| 6 | 18,83272727 | 0,167272727 | 0,418393181 |
| 7 | 21,13818182 | -0,138181818 | -0,34562915 |
| 8 | 23,44363636 | -0,043636364 | -0,109146047 |
| 9 | 25,74909091 | -0,149090909 | -0,372915662 |
| 10 | 28,05454545 | -0,254545455 | -0,636685276 |
Anhand dieses Teils des Berichts können wir die Abweichungen jedes Punkts von der konstruierten Regressionslinie sehen. Größter absoluter Wert
In seinen Werken aus dem Jahr 1908. Er beschrieb es am Beispiel der Arbeit eines Immobilienmaklers. In seinen Unterlagen erfasste der Hausverkaufsspezialist zahlreiche Eingabedaten für jedes einzelne Gebäude. Basierend auf den Ergebnissen der Auktion wurde ermittelt, welcher Faktor den größten Einfluss auf den Transaktionspreis hatte.
Analyse große Menge Transaktionen brachten interessante Ergebnisse. Der Endpreis wurde von vielen Faktoren beeinflusst, was manchmal zu paradoxen Schlussfolgerungen und sogar zu offensichtlichen „Ausreißern“ führte, wenn ein Haus mit hohem Anfangspotenzial zu einem reduzierten Preis verkauft wurde.
Das zweite Beispiel für die Anwendung einer solchen Analyse ist die Arbeit, deren Aufgabe darin bestand, die Vergütung der Arbeitnehmer festzulegen. Die Komplexität der Aufgabe lag darin, dass sie nicht die Verteilung eines festen Betrags an alle erforderte, sondern deren strikte Übereinstimmung mit der konkret geleisteten Arbeit. Das Aufkommen vieler Probleme mit praktisch ähnlichen Lösungen erforderte eine detailliertere Untersuchung dieser Probleme auf mathematischer Ebene.
Ein bedeutender Platz wurde dem Abschnitt „Regressionsanalyse“ eingeräumt, in dem praktische Methoden zur Untersuchung von Abhängigkeiten zusammengefasst wurden, die unter den Begriff der Regression fallen. Diese Beziehungen werden zwischen Daten aus statistischen Studien beobachtet.
Unter den vielen zu lösenden Problemen setzt er sich drei Hauptziele: die Bestimmung der Regressionsgleichung Gesamtansicht; Erstellen von Schätzungen von Parametern, die unbekannt sind und Teil der Regressionsgleichung sind; Prüfung statistischer Regressionshypothesen. Im Zuge der Untersuchung der Beziehung, die zwischen einem als Ergebnis experimenteller Beobachtungen erhaltenen Größenpaar und einer Reihe (Menge) des Typs (x1, y1), ..., (xn, yn) entsteht, stützen sie sich auf die Bestimmungen der Regressionstheorie und gehen davon aus, dass für eine Größe Y eine bestimmte Wahrscheinlichkeitsverteilung vorliegt, während die andere Größe X fest bleibt.
Das Ergebnis Y hängt vom Wert der Variablen X ab; diese Abhängigkeit kann durch verschiedene Muster bestimmt werden, während die Genauigkeit der erhaltenen Ergebnisse von der Art der Beobachtungen und dem Zweck der Analyse beeinflusst wird. Das experimentelle Modell basiert auf bestimmten Annahmen, die vereinfacht, aber plausibel sind. Die Hauptbedingung ist, dass der Parameter X eine kontrollierte Größe ist. Seine Werte werden vor Beginn des Experiments festgelegt.
Wenn während eines Experiments ein Paar unkontrollierter Variablen XY verwendet wird, wird die Regressionsanalyse auf die gleiche Weise durchgeführt, jedoch werden Methoden zur Interpretation der Ergebnisse verwendet, bei denen die Beziehung der untersuchten Zufallsvariablen untersucht wird. Methoden der mathematischen Statistik sind kein abstraktes Thema. Sie finden in den meisten Fällen Anwendung im Leben verschiedene Gebiete Menschliche Aktivität.
In der wissenschaftlichen Literatur wird zur Definition der oben genannten Methode häufig der Begriff lineare Regressionsanalyse verwendet. Für die Variable X wird der Begriff Regressor oder Prädiktor verwendet, abhängige Y-Variablen werden auch Kriteriumsvariablen genannt. Diese Terminologie spiegelt nur die mathematische Abhängigkeit der Variablen wider, nicht jedoch die Ursache-Wirkungs-Beziehung.
Die Regressionsanalyse ist die am häufigsten verwendete Methode zur Verarbeitung der Ergebnisse einer Vielzahl von Beobachtungen. Dabei werden physikalische und biologische Abhängigkeiten untersucht diese Methode Es wird sowohl in der Wirtschaft als auch in der Technologie umgesetzt. Viele andere Bereiche verwenden Regressionsanalysemodelle. Varianzanalyse, statistische Analyse multidimensional arbeiten eng mit dieser Studienmethode zusammen.
Besteht ein Zusammenhang zwischen Faktor und Leistungsmerkmalen, müssen Ärzte häufig feststellen, um wie viel sich der Wert eines Merkmals ändern kann, wenn das andere auf eine allgemein anerkannte oder vom Forscher selbst festgelegte Maßeinheit umgestellt wird.
Wie verändert sich beispielsweise das Körpergewicht von Erstklässlern (Mädchen oder Jungen), wenn ihre Körpergröße um 1 cm zunimmt? Hierzu wird die Methode der Regressionsanalyse eingesetzt.
Die Methode der Regressionsanalyse wird am häufigsten zur Entwicklung normativer Skalen und Standards verwendet körperliche Entwicklung.
- Definition von Regression. Regression ist eine Funktion, mit der Sie basierend auf dem Durchschnittswert eines Merkmals bestimmen können Durchschnittswert ein weiteres Merkmal korrelierte mit dem ersten.
Zu diesem Zweck wird ein Regressionskoeffizient verwendet und ganze Zeile andere Parameter. Sie können beispielsweise die durchschnittliche Anzahl der Erkältungen bei bestimmten Werten der durchschnittlichen monatlichen Lufttemperatur im Herbst-Winter-Zeitraum berechnen.
- Bestimmung des Regressionskoeffizienten. Regressionskoeffizienten - Absolutwert, um den sich im Durchschnitt der Wert eines Attributs ändert, wenn sich ein anderes zugehöriges Attribut um die festgelegte Maßeinheit ändert.
- Formel für den Regressionskoeffizienten. R y/x = r xy x (σ y / σ x)
wo R у/х - Regressionskoeffizient;
r xy – Korrelationskoeffizient zwischen den Merkmalen x und y;
(σ y und σ x) – Standardabweichungen der Merkmale x und y.In unserem Beispiel;
σ x = 4,6 (Standardabweichung der Lufttemperatur im Herbst-Winter-Zeitraum;
σ y = 8,65 (Standardabweichung der Anzahl an Infektions- und Erkältungskrankheiten).
Somit ist R y/x der Regressionskoeffizient.
R ó/х = -0,96 x (4,6 / 8,65) = 1,8, d.h. Wenn die durchschnittliche monatliche Lufttemperatur (x) um 1 Grad sinkt, ändert sich die durchschnittliche Anzahl von Infektions- und Erkältungskrankheiten (y) im Herbst-Winter-Zeitraum um 1,8 Fälle. - Regressionsgleichung. y = M y + R y/x (x - M x)
wobei y der Durchschnittswert des Merkmals ist, der ermittelt werden soll, wenn sich der Durchschnittswert eines anderen Merkmals ändert (x);
x ist der bekannte Durchschnittswert eines anderen Merkmals;
R y/x – Regressionskoeffizient;
M x, M y – bekannte Durchschnittswerte der Merkmale x und y.Beispielsweise kann die durchschnittliche Anzahl an Infektions- und Erkältungskrankheiten (y) ohne ermittelt werden Sondermaße bei jedem Durchschnittswert der durchschnittlichen monatlichen Lufttemperatur (x). Wenn also x = -9°, R y/x = 1,8 Krankheiten, M x = -7°, M y = 20 Krankheiten, dann ist y = 20 + 1,8 x (9-7) = 20 + 3,6 = 23,6 Krankheiten.
Diese Gleichung wird im Fall eines linearen Zusammenhangs zwischen zwei Merkmalen (x und y) angewendet. - Zweck der Regressionsgleichung. Die Regressionsgleichung wird verwendet, um eine Regressionsgerade zu erstellen. Letzteres ermöglicht es, ohne besondere Messungen einen beliebigen Durchschnittswert (y) eines Merkmals zu ermitteln, wenn sich der Wert (x) eines anderen Merkmals ändert. Basierend auf diesen Daten wird ein Diagramm erstellt - Regressionslinie, mit dem die durchschnittliche Anzahl der Erkältungen bei jedem Wert der durchschnittlichen monatlichen Temperatur im Bereich zwischen den berechneten Werten der Anzahl der Erkältungen ermittelt werden kann.
- Regression Sigma (Formel).
wobei σ Rу/х – Sigma (Standardabweichung) der Regression;
σ y - Standardabweichung des Merkmals y;
r xy – Korrelationskoeffizient zwischen den Merkmalen x und y.Wenn also σ y - Standardabweichung der Anzahl der Erkältungen = 8,65; r xy - der Korrelationskoeffizient zwischen der Anzahl der Erkältungen (y) und der durchschnittlichen monatlichen Lufttemperatur im Herbst-Winter-Zeitraum (x) beträgt dann - 0,96

- Regressions-Sigma-Zuordnung. Gibt eine Beschreibung des Diversitätsmaßes des resultierenden Merkmals (y).
Es charakterisiert beispielsweise die Vielfalt der Erkältungszahlen bei einem bestimmten Wert der durchschnittlichen monatlichen Lufttemperatur im Herbst-Winter-Zeitraum. Somit kann die durchschnittliche Anzahl an Erkältungen bei Lufttemperatur x 1 = -6° zwischen 15,78 und 20,62 Erkrankungen liegen.
Bei x 2 = -9° kann die durchschnittliche Anzahl an Erkältungen zwischen 21,18 Krankheiten und 26,02 Krankheiten usw. liegen.Regressionssigma wird verwendet, um eine Regressionsskala zu erstellen, die die Abweichung der Werte des resultierenden Merkmals von seinem auf der Regressionslinie aufgetragenen Durchschnittswert widerspiegelt.
- Daten, die zur Berechnung und Darstellung der Regressionsskala erforderlich sind
- Regressionskoeffizient - R у/х;
- Regressionsgleichung - y = M y + R y/x (x-M x);
- Regressionssigma - σ Rx/y
- Reihenfolge der Berechnungen und grafische Darstellung der Regressionsskala.
- Bestimmen Sie den Regressionskoeffizienten anhand der Formel (siehe Absatz 3). Beispielsweise muss ermittelt werden, wie stark sich das Körpergewicht im Durchschnitt (in einem bestimmten Alter je nach Geschlecht) ändert, wenn sich die durchschnittliche Körpergröße um 1 cm ändert.
- Bestimmen Sie mithilfe der Regressionsgleichungsformel (siehe Punkt 4), wie hoch beispielsweise das Körpergewicht im Durchschnitt (y, y 2, y 3 ...) * für einen bestimmten Körpergrößenwert (x, x 2, x 3) sein wird. ..) .
________________
* Der Wert von „y“ sollte für mindestens drei bekannte Werte von „x“ berechnet werden.Gleichzeitig sind die Durchschnittswerte von Körpergewicht und Körpergröße (M x und M y) für ein bestimmtes Alter und Geschlecht bekannt
- Berechnen Sie das Regressionssigma, indem Sie die entsprechenden Werte von σ y und r xy kennen und ihre Werte in die Formel einsetzen (siehe Absatz 6).
- basierend auf den bekannten Werten x 1, x 2, x 3 und den entsprechenden Durchschnittswerten y 1, y 2 y 3, sowie dem kleinsten (y - σ rу/х) und größten (y + σ rу /х) Werte (y) konstruieren eine Regressionsskala.
Um die Regressionsskala grafisch darzustellen, werden zunächst die Werte x, x2, x3 (Ordinatenachse) auf dem Diagramm markiert, d.h. Es wird eine Regressionsgerade erstellt, beispielsweise die Abhängigkeit des Körpergewichts (y) von der Körpergröße (x).
Dann werden an den entsprechenden Punkten 1, y 2, y 3 die Zahlenwerte des Regressionssigmas notiert, d.h. Finden Sie den kleinsten in der Grafik und Höchster Wert J 1, J 2, J 3.
- Praktischer Nutzen Regressionsskalen. Insbesondere für die körperliche Entwicklung werden normative Skalen und Standards entwickelt. Anhand einer Standardskala können Sie eine individuelle Einschätzung der kindlichen Entwicklung abgeben. In diesem Fall wird die körperliche Entwicklung als harmonisch beurteilt, wenn beispielsweise bei einer bestimmten Körpergröße das Körpergewicht des Kindes innerhalb eines Sigmas der Regression auf die durchschnittliche berechnete Körpergewichtseinheit - (y) für eine bestimmte Körpergröße (x) liegt ( y ± 1 σ Ry/x).
Die körperliche Entwicklung gilt in Bezug auf das Körpergewicht als disharmonisch, wenn das Körpergewicht des Kindes für eine bestimmte Körpergröße innerhalb des zweiten Sigmas der Regression liegt: (y ± 2 σ Ry/x)
Die körperliche Entwicklung wird aufgrund von überschüssigem und unzureichendem Körpergewicht stark unharmonisch sein, wenn das Körpergewicht für eine bestimmte Körpergröße innerhalb des dritten Sigmas der Regression (y ± 3 σ Ry/x) liegt.
Den Ergebnissen zufolge statistische Forschung Für die körperliche Entwicklung von 5-jährigen Jungen ist bekannt, dass ihre durchschnittliche Körpergröße (x) 109 cm und das durchschnittliche Körpergewicht (y) 19 kg beträgt. Der Korrelationskoeffizient zwischen Körpergröße und Körpergewicht beträgt +0,9, Standardabweichungen sind in der Tabelle dargestellt.
Erforderlich:
- Berechnen Sie den Regressionskoeffizienten.
- Bestimmen Sie mithilfe der Regressionsgleichung das erwartete Körpergewicht von 5-jährigen Jungen mit einer Körpergröße von x1 = 100 cm, x2 = 110 cm, x3 = 120 cm.
- Berechnen Sie das Regressionssigma, erstellen Sie eine Regressionsskala und stellen Sie die Ergebnisse ihrer Lösung grafisch dar.
- entsprechende Schlussfolgerungen ziehen.
Die Bedingungen des Problems und die Ergebnisse seiner Lösung werden in der Übersichtstabelle dargestellt.
Tabelle 1
| Bedingungen des Problems | Ergebnisse der Lösung des Problems | ||||||||
| Regressionsgleichung | Regressions-Sigma | Regressionsskala (erwartetes Körpergewicht (in kg)) | |||||||
| M | σ | r xy | R y/x | X | U | σ R x/y | y - σ Rû/х | y + σ Rû/х | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Höhe (x) | 109 cm | ± 4,4 cm | +0,9 | 0,16 | 100cm | 17,56 kg | ± 0,35 kg | 17,21 kg | 17,91 kg |
| Körpermasse (y) | 19 kg | ± 0,8 kg | 110 cm | 19,16 kg | 18,81 kg | 19,51 kg | |||
| 120 cm | 20,76 kg | 20,41 kg | 21,11 kg | ||||||
Lösung.
Abschluss. Somit ermöglicht die Regressionsskala im Rahmen der berechneten Körpergewichtswerte die Bestimmung bei jedem anderen Körpergrößenwert oder die Beurteilung der individuellen Entwicklung des Kindes. Stellen Sie dazu die Senkrechte zur Regressionsgeraden wieder her.
- Wlassow V.V. Epidemiologie. - M.: GEOTAR-MED, 2004. - 464 S.
- Lisitsyn Yu.P. Öffentliche Gesundheit und Gesundheitswesen. Lehrbuch für Universitäten. - M.: GEOTAR-MED, 2007. - 512 S.
- Medic V.A., Yuryev V.K. Vorlesungsreihe zum Thema öffentliche Gesundheit und Gesundheitsfürsorge: Teil 1. Öffentliche Gesundheit. - M.: Medizin, 2003. - 368 S.
- Minyaev V.A., Vishnyakov N.I. usw. Sozialmedizin und Gesundheitsorganisation (Handbuch in 2 Bänden). - St. Petersburg, 1998. -528 S.
- Kucherenko V.Z., Agarkov N.M. und andere. Soziale Hygiene- und Gesundheitsorganisation ( Lernprogramm) - Moskau, 2000. - 432 S.
- S. Glanz. Medizinische und biologische Statistik. Übersetzung aus dem Englischen - M., Praktika, 1998. - 459 S.