Conférences sur les statistiques. Présentation graphique des informations statistiques
Lire aussi
Les données statistiques doivent être présentées de manière à pouvoir être utilisées. Il existe 3 formes principales de présentation des données statistiques :
1) texte - l'inclusion de données dans le texte;
2) tabulaire - présentation des données dans des tableaux ;
3) graphique - l'expression de données sous forme de graphiques.
La forme texte est utilisée lorsqu'il y a une petite quantité de données numériques.
La forme tabulaire est la plus utilisée, car elle est plus forme efficace présentation des données statistiques. Contrairement aux tables mathématiques qui, selon les conditions initiales, permettent d'obtenir tel ou tel résultat, les tables statistiques racontent le langage des nombres sur les objets étudiés.
Tableau statistique- il s'agit d'un système de lignes et de colonnes, dans lequel les informations statistiques sur les phénomènes socio-économiques sont présentées dans une certaine séquence et connexion.
Tableau 2. Commerce extérieur de la Fédération de Russie pour 2000 - 2006, milliards de dollars
| Indice | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 |
| Chiffre d'affaires du commerce extérieur | 149,9 | 155,6 | 168,3 | 280,6 | 368,9 | 468,4 | |
| Exporter | 101,9 | 107,3 | 135,9 | 183,2 | 243,6 | 304,5 | |
| Importer | 44,9 | 53,8 | 76,1 | 97,4 | 125,3 | 163,9 | |
| Balance commerciale | 60,1 | 48,1 | 46,3 | 59,9 | 85,8 | 118,3 | 140,7 |
| y compris: | |||||||
| avec des pays étrangers | |||||||
| exporter | 90,8 | 86,6 | 90,9 | 114,6 | 210,1 | 261,1 | |
| importer | 31,4 | 40,7 | 48,8 | 77,5 | 103,5 | 138,6 | |
| balance commerciale | 59,3 | 45,9 | 42,1 | 53,6 | 75,5 | 106,6 | 122,5 |
Par exemple, dans le tableau. 2 présente des informations sur le commerce extérieur de la Russie, qu'il serait inefficace d'exprimer sous forme textuelle.
Distinguer matière et prédicat tableau statistique. Le sujet indique l'objet caractérisé - soit des unités de la population, soit des groupes d'unités, soit la totalité dans son ensemble. Dans le prédicat, la caractéristique du sujet est donnée, généralement sous forme numérique. Obligatoire entête table, qui indique à quelle catégorie et à quelle heure appartiennent les données de la table.
Selon la nature du sujet, les tableaux statistiques sont divisés en Facile, groupe et combinatoire. Dans le sujet d'un tableau simple, l'objet d'étude n'est pas divisé en groupes, mais soit une liste de toutes les unités de la population est donnée, soit la population dans son ensemble est indiquée (par exemple, tableau 11). Dans le sujet du tableau de groupe, l'objet d'étude est divisé en groupes selon un attribut, et le prédicat indique le nombre d'unités dans les groupes (absolu ou en pourcentage) et des indicateurs récapitulatifs pour les groupes (par exemple, Tableau 4). Dans le sujet du tableau de combinaison, la population est divisée en groupes non pas selon un, mais selon plusieurs critères (par exemple, tableau 2).
Lors de la construction de tableaux, vous devez être guidé par les éléments suivants règles générales.
1. Le sujet du tableau est situé dans la partie gauche (moins souvent - supérieure) et le prédicat - dans la partie droite (moins souvent - inférieure).
2. Les en-têtes de colonne contiennent les noms des indicateurs et leurs unités.
3. La dernière ligne complète le tableau et se situe à son extrémité, mais parfois c'est la première : dans ce cas, la deuxième ligne est écrite « y compris », et les lignes suivantes contiennent les composants de la ligne totale.
4. Les données numériques sont écrites avec le même degré de précision dans chaque colonne, avec les chiffres des nombres situés sous les chiffres, et la partie entière est séparée de la virgule fractionnaire.
5. Il ne doit pas y avoir de cellules vides dans le tableau : si les données sont nulles, le signe "-" (tiret) est mis ; si les données ne sont pas connues, l'entrée «aucune information» est faite ou le signe «…» (points de suspension) est mis. Si la valeur de l'exposant n'est pas zéro, mais que le premier chiffre significatif apparaît après le degré de précision accepté, alors 0,0 est enregistré (si, par exemple, un degré de précision de 0,1 a été accepté).
Parfois, les tableaux statistiques sont complétés par des graphiques lorsque le but est de mettre en évidence certaines caractéristiques des données, de les comparer. La forme graphique est la forme la plus efficace de présentation des données en termes de perception. À l'aide de graphiques, la visibilité des caractéristiques de la structure, de la dynamique, de la relation des phénomènes et de leur comparaison est obtenue.
Graphiques statistiques- ce sont des images conditionnelles de valeurs numériques et de leurs rapports à travers des lignes, des formes géométriques, des dessins ou des cartes géographiques. La forme graphique facilite la prise en compte des données statistiques, les rend visuelles, expressives et visibles. Cependant, les graphiques ont certaines limites : tout d'abord, un graphique ne peut pas inclure autant de données qu'il peut contenir dans un tableau ; de plus, le graphique affiche toujours des données arrondies - pas exactes, mais approximatives. Ainsi, le graphique n'est utilisé que pour montrer la situation générale, pas les détails. Le dernier inconvénient est la complexité du tracé. Il peut être surmonté en utilisant ordinateur personnel(par exemple, "Chart Wizard" du package Microsoft Office Excel).
Selon la méthode de construction des graphiques, ils sont divisés en diagrammes, cartogrammes et diagrammes graphiques.
Le moyen le plus courant de représentation graphique des données sont les graphiques, qui sont des types suivants : linéaire, radial, dispersé, planaire, volumétrique, bouclé. Le type de diagrammes dépend du type de données présentées et de la tâche de construction. Dans tous les cas, le graphique doit être accompagné d'un titre - au-dessus ou au-dessous du champ du graphique. Le titre indique quel indicateur est affiché, pour quel territoire et pour quelle heure.
Les graphiques linéaires sont utilisés pour représenter des variables quantitatives : caractéristiques de la variation de leurs valeurs, dynamique, relations entre variables. La variation des données est analysée à l'aide de zone de diffusion, cumule(inférieur à la courbe) et ogives(courbe "supérieur à"). Le polygone de distribution est discuté dans le Thème 4 (par exemple Fig. 5.). Pour construire un cumulé, les valeurs de la caractéristique variable sont tracées le long de l'abscisse, et les ordonnées sont les totaux cumulés des fréquences ou des fréquences (de f1à ∑ F). Pour construire une ogive, les totaux cumulés des fréquences sont placés sur l'axe des ordonnées dans l'ordre inverse (de ∑ F avant de f1). Cumulez et ogivez selon le tableau. 4. décrivez à la fig. une.
Riz. 1. Cumuls et ogives de la répartition des marchandises selon la valeur en douane
L'utilisation des graphiques linéaires dans l'analyse des tendances est traitée dans le Thème 5 (par exemple la Figure 13) et leur utilisation pour l'analyse des liens dans le Thème 6 (par exemple la Figure 21). Le sujet 6 couvre également l'utilisation des nuages de points (par exemple la figure 20).
Les graphiques linéaires sont subdivisés en unidimensionnel, utilisé pour représenter des données sur une seule variable, et bidimensionnel- pour deux variables. Un exemple d'une dimension graphique linéaire est le polygone de la distribution, et celui bidimensionnel est la ligne de régression (par exemple, Fig. 21).
Parfois quand grands changements recours à une échelle logarithmique. Par exemple, si les valeurs d'un indicateur varient de 1 à 1000, cela peut entraîner des difficultés lors du traçage. Dans de tels cas, ils passent aux logarithmes des valeurs de l'indicateur, qui ne différeront pas tellement : lg 1 = 0, lg 1000 = 3.
Parmi planaire Les graphiques à barres (histogrammes) se distinguent en fonction de la fréquence d'utilisation, dans lesquels l'indicateur est présenté sous la forme d'une barre dont la hauteur correspond à la valeur de l'indicateur (par exemple, Fig. 4).
La proportionnalité de l'aire d'une figure géométrique particulière à la valeur de l'indicateur sous-tend d'autres types de diagrammes planaires : triangulaire, carré, rectangulaire. Vous pouvez également utiliser une comparaison des aires d'un cercle - dans ce cas, le rayon du cercle est défini.
Bande dessinée présente des indicateurs sous la forme de rectangles étirés horizontalement, et est par ailleurs identique à un graphique à barres.
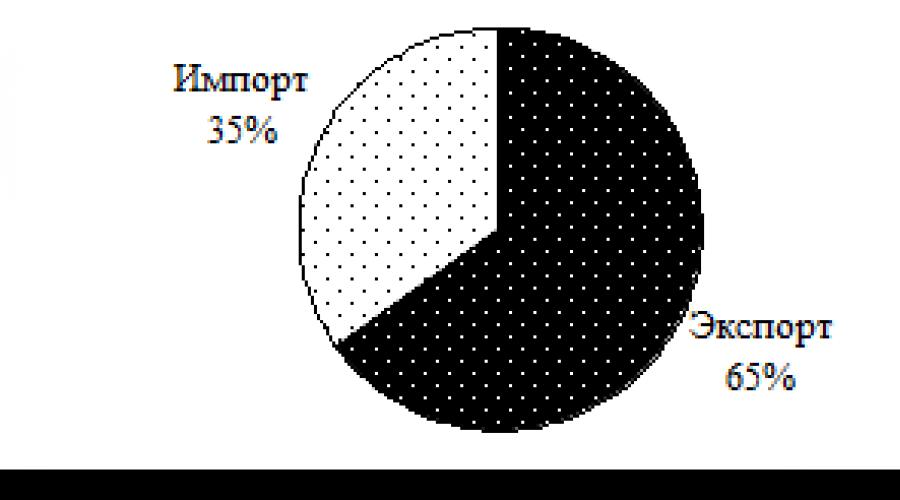
Parmi les diagrammes planaires, il est souvent utilisé diagramme circulaire, qui sert à illustrer la structure de la population étudiée. L'ensemble est pris à 100%, il correspond à l'aire totale du cercle, les aires des secteurs correspondent à des parties de l'ensemble. Construisons un diagramme sectoriel de la structure du commerce extérieur de la Fédération de Russie en 2006 selon le tableau. 2 (voir fig. 2). Utilisant logiciels d'ordinateur les diagrammes de secteur sont construits sous forme tridimensionnelle, c'est-à-dire non pas en deux, mais en trois plans (voir Fig. 3).


Riz. 2. Graphique circulaire simple 3. Graphique circulaire 3D
Les diagrammes bouclés (image) améliorent la clarté de l'image, car ils incluent une image de l'indicateur affiché, dont la taille correspond à la taille de l'indicateur.
Lorsque vous tracez un graphique, tout est également important - bon choix image graphique, proportions, respect des règles de conception des graphiques. Ces questions sont traitées plus en détail dans et.
Cartogrammes et cartogrammes sont appliqués à l'image caractéristiques géographiques phénomènes étudiés. Ils montrent la localisation du phénomène étudié, son intensité sur un certain territoire - dans une république, une région, un district économique ou administratif, etc. La construction de cartogrammes et de cartogrammes est envisagée dans la littérature spécialisée, par exemple.
Fin du travail -
Ce sujet appartient à :
Le concept de statistiques. Le sujet et la méthode des statistiques
Le concept de statistique.. sujet et méthode de statistique.. observation statistique..
Si vous avez besoin de matériel supplémentaire sur ce sujet, ou si vous n'avez pas trouvé ce que vous cherchiez, nous vous recommandons d'utiliser la recherche dans notre base de données d'œuvres :
Que ferons-nous du matériel reçu :
Si ce matériel s'est avéré utile pour vous, vous pouvez l'enregistrer sur votre page sur les réseaux sociaux :
| tweeter |
Tous les sujets de cette section :
Le sujet et la méthode des statistiques
Le terme "statistiques" a été introduit dans l'usage scientifique par le scientifique allemand Gottfried Achenwal en 1746, qui a proposé de remplacer le titre du cours "Statistiques" enseigné dans les universités allemandes par "St
Observation statistique
Les gens ont des attitudes différentes à l'égard de l'information statistique : certains ne la perçoivent pas, d'autres y croient inconditionnellement, et d'autres encore sont d'accord avec l'opinion de l'homme politique anglais Disraeli : « Il y a 3 types de mensonges : mensonges,
Synthèse et regroupement des statistiques
Résumé - traitement scientifiquement organisé des matériaux d'observation (selon un programme préalablement développé), qui comprend, outre le contrôle obligatoire des données collectées, la systématisation, le regroupement
Valeurs absolues
Pour caractériser les phénomènes de masse, la statistique utilise statistiques(indicateurs) qui caractérisent des groupes d'unités ou un agrégat (phénomène) dans son ensemble. Grandeurs statistiques
Valeurs relatives
Une valeur relative est le résultat de la division (comparaison) de deux valeurs absolues. Le numérateur de la fraction est la valeur comparée et le dénominateur est la valeur comparée à (ba
Valeurs moyennes
Comme cela a été dit à maintes reprises, la statistique étudie les phénomènes et les processus de masse. Chacun de ces phénomènes a à la fois des propriétés communes à l'ensemble et des propriétés particulières, individuelles.
Construire une série de distribution
Les caractéristiques étudiées par les statistiques varient (diffèrent les unes des autres) pour différentes unités de la population au cours de la même période ou à un moment précis. Par exemple, la valeur du chiffre d'affaires du commerce extérieur varie
Calcul des caractéristiques structurelles de la série de distribution
Lors de l'étude de la variation, on utilise de telles caractéristiques d'une série de distribution qui décrivent quantitativement sa structure, sa structure. Telle est, par exemple, la médiane - la valeur de l'attribut variable
Calcul des mesures de taille et d'intensité de variation
L'indicateur le plus simple est la plage de variation - la différence absolue entre les valeurs maximales et minimales d'un trait par rapport aux valeurs disponibles dans la population étudiée (24):
Calcul des moments de distribution et indicateurs de sa forme
Pour une étude plus approfondie de la nature de la variation, les valeurs moyennes sont utilisées différents degrésécarts des valeurs individuelles d'un trait par rapport à sa valeur moyenne arithmétique. Ces indicateurs sont appelés
Vérifier si la série de distribution est normale
La courbe de distribution théorique s'entend comme une représentation graphique d'une série sous la forme d'une ligne continue de changement de fréquence dans une série variationnelle, fonctionnellement associée à un changement d'options, autre
Vérifier si la série de distribution est conforme à la loi de Poisson
L'inspection des douanes effectuait un contrôle après la mainlevée des marchandises. En conséquence, la série de distribution discrète suivante du nombre de violations identifiées dans chaque test a été obtenue (tableau 16). Tableau 1
Indicateurs absolus et relatifs de changement de structure
Le développement d'une population statistique se manifeste non seulement par la croissance ou la diminution quantitative des éléments du système, mais aussi par une modification de sa structure. La structure est la structure de l'agrégat
Indicateurs de classement du changement de structure
Pour mesurer les différences dans la structure, moins précises, mais plus faciles à calculer, on utilise souvent des indicateurs basés sur l'évaluation des différences non pas dans les valeurs des actions elles-mêmes, mais dans leurs rangs, c'est-à-dire ordinaux
Le concept d'observation sélective
La méthode d'échantillonnage est utilisée lorsque l'utilisation de l'observation continue est physiquement impossible en raison d'une énorme quantité de données ou n'est pas économiquement réalisable. Il y a une impossibilité physique
Méthodes d'échantillonnage
1. Sélection réellement aléatoire : toutes les unités du SH sont numérotées, et les numéros tirés à la suite du tirage correspondent aux unités qui sont tombées dans l'échantillon, et le nombre de numéros est égal au nombre prévu
Erreur d'échantillonnage moyenne
Après avoir terminé la sélection du nombre requis d'unités dans l'échantillon et enregistré les caractéristiques de ces unités prévues par le programme d'observation, ils procèdent au calcul des indicateurs de généralisation. à eux de
Erreur d'échantillonnage marginale
Considérant que sur la base d'une enquête par sondage, il est impossible d'évaluer avec précision le caractère généralisant du SH, il est nécessaire de trouver les limites dans lesquelles il se situe. Dans un échantillon particulier, la différence
Taille d'échantillon requise
Lors de l'élaboration d'un programme d'observation sélective, on leur attribue une valeur spécifique de l'erreur marginale et du niveau de probabilité. La taille minimale de l'échantillon qui fournit un
Des lignes directrices
Une tâche. Dans l'entreprise, 100 travailleurs sur 1000 ont été interrogés dans l'ordre d'un échantillon aléatoire non répétitif et les données suivantes ont été obtenues sur leur revenu du mois (tableau 24) : Ta
Le concept de séries temporelles
Un des tâches critiques la statistique est l'étude de l'évolution des indicateurs analysés dans le temps, c'est-à-dire de leur dynamique. Ce problème est résolu en analysant la série de dynamiques (séries temporelles).
Indicateurs de changements dans les niveaux d'une série de dynamiques
L'analyse des séries chronologiques commence par déterminer comment les niveaux de la série changent (augmentent, diminuent ou restent inchangés) en termes absolus et relatifs. Tracer
Indicateurs moyens d'une série de dynamiques
Chaque série de dynamiques peut être considérée comme un certain ensemble de n indicateurs évoluant dans le temps, qui peuvent être résumés en valeurs moyennes. Ces indicateurs généralisés (moyens) sont particulièrement
Méthodes d'identification de la tendance principale (tendance) dans la série de dynamiques
L'une des principales tâches de l'étude de la série de dynamiques est d'identifier la tendance principale (modèle) dans l'évolution des niveaux de la série, appelée tendance. Régularité dans le changement des niveaux d'une série dans certains cas
Évaluation et prévision de l'adéquation des tendances
Pour l'équation de tendance trouvée, il est nécessaire d'évaluer sa fiabilité (adéquation), qui est généralement effectuée à l'aide du critère de Fisher, en comparant sa valeur calculée Fр
Analyse saisonnière
Dans la série de dynamiques, dont les niveaux sont des indicateurs mensuels ou trimestriels, ainsi que des fluctuations aléatoires, on observe souvent des fluctuations saisonnières, qui sont comprises comme périodiquement
Des lignes directrices
Selon le Service fédéral des statistiques de l'État, le solde du commerce extérieur (SVT) de la Russie pour la période 2000-2006. caractérisé par un certain nombre de dynamiques présentées dans le tableau. 36. Tableau 36. Balance commerciale extérieure (CBT) de la Russie pour p
Le concept de dépendance de corrélation
L'une des lois les plus générales du monde objectif est la loi de la connexion universelle et de la dépendance entre les phénomènes. Naturellement, lorsqu'il s'agit d'enquêter sur des phénomènes dans les domaines les plus divers, les statistiques se heurtent inévitablement
Méthodes d'identification et d'évaluation des corrélations
Un certain nombre de méthodes sont utilisées en statistique pour identifier la présence et la nature d'une corrélation entre deux caractéristiques. 1. Prise en compte des données parallèles (kn
Coefficients de corrélation de rang
Les coefficients de corrélation de rang sont des indicateurs non paramétriques moins précis, mais plus faciles à calculer, pour mesurer la proximité de la relation entre deux caractéristiques corrélées. Ceux-ci inclus
Particularités de la corrélation des séries chronologiques
Dans de nombreuses études, il est nécessaire d'étudier la dynamique de plusieurs indicateurs simultanément, c'est-à-dire considérer plusieurs séries temporelles en parallèle. Dans ce cas, il devient nécessaire de mesurer la dépendance
Indicateurs de l'étroitesse de la relation entre les caractéristiques qualitatives
La méthode des tableaux de corrélation s'applique non seulement aux caractéristiques quantitatives, mais également aux caractéristiques descriptives (qualitatives), dont la relation entre elles doit souvent être étudiée lors de la conduite de divers sociologues.
Corrélation multiple
Lors de la résolution de problèmes pratiques, les chercheurs sont confrontés au fait que les corrélations ne se limitent pas aux relations entre deux caractéristiques : y effectif et facteur x. En action
Objet et types d'indices
L'indice est une valeur relative montrant combien de fois le niveau du phénomène étudié dans des conditions données diffère du niveau du même phénomène dans d'autres conditions. La différence de conditions peut être
Indices individuels
La valeur relative obtenue en comparant les niveaux est appelée indice individuel si la structure du phénomène étudié importe peu. Indices individuels dénoté je
Index généraux
Si le phénomène étudié est hétérogène et que les niveaux ne peuvent être comparés qu'après avoir été réduits à mesure générale, l'analyse économique est effectuée au moyen d'indices généraux. L'indice devient général
Indices moyens
Lors de l'étude d'indicateurs qualitatifs, il est souvent nécessaire de considérer l'évolution dans le temps (ou dans l'espace) de la valeur moyenne d'un indicateur indexé pour une certaine population homogène.
Indices territoriaux
Les indices territoriaux sont utilisés pour les comparaisons spatiales et interrégionales de divers indicateurs. Leur calcul est plus compliqué que le calcul des indices traditionnels (dynamiques) considérés
:
Forme de texte
forme tabulaire
Tableau statistique
Les graphiques statistiques sont des images conditionnelles de valeurs numériques et de leurs rapports à travers des lignes, des formes géométriques, des dessins ou des cartes géographiques. La forme graphique facilite la prise en compte des données statistiques, les rend visuelles, expressives et visibles. Cependant, les graphiques ont certaines limites : tout d'abord, un graphique ne peut pas inclure autant de données qu'il peut contenir dans un tableau ; de plus, le graphique affiche toujours des données arrondies - pas exactes, mais approximatives. Ainsi, le graphique n'est utilisé que pour montrer la situation générale, pas les détails. Le dernier inconvénient est la complexité du tracé. Il peut être surmonté à l'aide d'un ordinateur personnel (par exemple, le "Chart Wizard" du package Microsoft Office Excel).
Détermination de la fonction de distribution empirique.
Exemple de fonction de distribution (empirique) en statistique mathématique, il s'agit d'une approximation d'une fonction de distribution théorique construite à partir d'un échantillon de celle-ci.
Définition
Soit un échantillon de la distribution d'une variable aléatoire donnée par la fonction de distribution . Nous supposons que , où , sont des variables aléatoires indépendantes définies sur un certain espace de résultats élémentaires . Laisser . Définissons une variable aléatoire ![]() de la manière suivante :
de la manière suivante :
où est l'indicateur d'événement , est la fonction Heaviside. Ainsi, la fonction de distribution d'échantillonnage en un point est égale à la fréquence relative des éléments d'échantillon qui ne dépassent pas la valeur . La variable aléatoire est appelée la fonction de distribution d'échantillon de la variable aléatoire et est une approximation de la fonction . Il existe un résultat montrant que pour , la fonction converge uniformément vers , et indiquant le taux de convergence.
diagramme à bandes
Un histogramme est utilisé pour représenter graphiquement les distributions traits continuellement variables et se compose de rectangles adjacents, comme illustré à la Fig. 2.1. La base de chaque rectangle est égale à la largeur de l'intervalle de regroupement, et sa hauteur est telle que carré rectangle est proportionnel à la fréquence (ou fréquence) d'atteinte de l'intervalle donné. Si la ligne n'est pas un intervalle, la largeur de toutes les colonnes est choisie arbitrairement, mais la même. Ainsi, les hauteurs des rectangles doivent être proportionnelles aux valeurs
où n je- la fréquence je-ième intervalle de regroupement ; salut- largeur je-ième intervalle de regroupement.
Sur l'histogramme, la base des rectangles est tracée le long de l'axe des x ( X), et la hauteur est le long de l'axe y ( à) d'un système de coordonnées rectangulaires.
Cependant, dans les cas où la largeur de tous les intervalles de regroupement est la même, l'apparence de l'histogramme ne changera pas si les valeurs ne sont pas tracées le long de l'axe y p je, et fréquences d'intervalle n je.

Riz. 2.1. Histogramme de la distribution des résultats dans l'exemple précédent (lorsque la largeur de certains intervalles de regroupement n'est pas la même).
Dans ce cas, pour ne pas violer le principe de construction d'un histogramme (les aires des rectangles sont proportionnelles aux fréquences des intervalles), on ne peut plus tracer les fréquences en ordonnée, mais les hauteurs des rectangles (qui doit être proportionnel aux rapports) doit être tracé.
Polygone de fréquence
Une autre représentation graphique courante est le polygone de fréquence.
Le polygone de fréquence est formé par une ligne brisée reliant les points correspondant aux valeurs médianes des intervalles de regroupement et les fréquences de ces intervalles, les valeurs médianes sont tracées le long de l'axe X, et fréquences - le long de l'axe à.
D'une comparaison des deux méthodes considérées de représentation graphique des distributions empiriques, il ressort que pour obtenir un polygone de fréquence à partir de l'histogramme construit, il est nécessaire de relier les milieux des sommets des rectangles qui forment l'histogramme en reliant des droites segments de ligne. Un exemple de polygone de fréquence est illustré à la fig. 2.2.
Riz. 2.2. Polygone de fréquence
Le polygone de fréquence est utilisé pour représenter les distributions des entités continues et discrètes. Dans le cas d'une distribution continue, un polygone de fréquence est un mode de représentation graphique plus préférable qu'un histogramme, si le tracé de la distribution empirique est décrit par une dépendance lisse.
21.Hypothèse(grec ancien ὑπόθεσις - hypothèse; de ὑπό - d'en bas, sous + θέσις - thèse) - hypothèse ou conjecture; un énoncé qui présuppose une preuve, par opposition aux axiomes
Postulats qui ne nécessitent pas de preuve. Une hypothèse est considérée comme scientifique si elle satisfait au critère de Popper, c'est-à-dire peut potentiellement être testé par une expérience critique, ainsi que s'il répond à d'autres critères qui distinguent la science de la non-science.
Hypothèse statistique est une hypothèse sur les propriétés des variables aléatoires ou des événements que nous voulons tester par rapport aux données disponibles. Exemples d'hypothèses statistiques dans recherche pédagogique :
Hypothèse 1. La performance d'une classe dépend stochastiquement (probablement) du niveau d'apprentissage des élèves.
Hypothèse 2. L'assimilation du cours initial de mathématiques ne présente pas de différences significatives chez les élèves qui ont commencé leurs études à l'âge de 6 ou 7 ans.
Hypothèse 3. L'apprentissage par problèmes en première année est plus efficace que les méthodes d'enseignement traditionnelles en ce qui concerne développement généralétudiants.
Exemple 1 Le processus de fabrication de certains produits médicaux est très compliqué. À première vue, des écarts insignifiants par rapport à la technologie provoquent l'apparition d'une impureté latérale hautement toxique. La toxicité de cette impureté peut s'avérer si élevée que même une telle quantité qui ne peut pas être détectée avec des analyse chimique peut être dangereux pour la personne qui prend ce médicament. Ainsi, avant la mise sur le marché d'un lot nouvellement produit, celui-ci est soumis à une étude de toxicité par des méthodes biologiques. De petites doses du médicament sont administrées à un certain nombre d'animaux de laboratoire, tels que des souris, et le résultat est enregistré. Si le médicament est toxique, alors tous ou presque tous les animaux meurent. Sinon, le taux de survivants est élevé.
L'investigation d'un médicament peut conduire à l'un des les voies possibles actions : libérer le lot pour la vente (a 1), retourner le lot au fournisseur pour révision ou, éventuellement, pour destruction (a 2).
Les deux types d'erreurs associées aux actions a 1 et a 2 sont complètement différents, et l'importance de les éviter est également différente. Considérons d'abord le cas où l'action a 1 est appliquée, alors que a 2 est préférable. Le médicament est dangereux pour le patient, alors qu'il est reconnu comme sûr. Une erreur de ce genre peut entraîner la mort chez les patients utilisant ce médicament. Il s'agit d'une erreur de type I, car il est plus important pour nous de l'éviter.
Considérons le cas où l'action a 2 est prise alors qu'un 1 est plus préférable. Cela signifie qu'en raison d'imprécisions dans la conduite de l'expérience, le lot de médicament non toxique a été classé comme dangereux. Les conséquences d'une erreur peuvent se traduire par une perte financière et par une augmentation du coût du médicament. Cependant, le rejet accidentel d'un médicament parfaitement sûr est évidemment moins indésirable que la mort occasionnelle de patients. Le rejet d'un lot non toxique d'un médicament est une erreur de type II.
Probabilité d'erreur de type I admissible(Rkr) peut être égal à 5 % ou 1 % (0,05 ou 0,01).
22. Test d'hypothèse statistique(tester des hypothèses statistiques) est le processus consistant à décider si une hypothèse statistique donnée est incompatible avec un échantillon de données observé.
test statistique ou test statistique- une règle mathématique stricte par laquelle est accepté ou rejeté hypothèse statistique.
· 23.classification des hypothèses
· Facile- une circonstance est indiquée, en présence ou en l'absence de laquelle la norme juridique est valide ;
· complexe- la présence dans l'hypothèse de deux ou plusieurs circonstances à la fois, qui ensemble déterminent le fonctionnement de la norme ;
· alternative- plusieurs variantes de circonstances (alternatives) sont indiquées dans lesquelles la règle peut être appliquée. Dans ce cas, lorsque l'un d'eux se produit, la norme est valide ;
hypothèse paramétrique appelé l'hypothèse valeurs des paramètres de distribution ou sur la valeur comparative des paramètres de deux distributions. Un exemple d'hypothèse statistique paramétrique est l'hypothèse sur égalité des espérances mathématiques deux séries normales.
Hypothèses non paramétriques appelées hypothèses sur distribution aléatoire quantités.
Nul, l'hypothèse principale ou testée est l'hypothèse émise à l'origine, qui est notée H0.
Hypothèse statistique représente une hypothèse sur la loi de distribution d'une variable aléatoire ou sur les paramètres de cette loi, formulée à partir d'un échantillon. Des exemples d'hypothèses statistiques sont les hypothèses : la population générale est distribuée selon la loi exponentielle ; les attentes mathématiques de deux échantillons distribués de manière exponentielle sont égales l'une à l'autre. Dans le premier d'entre eux, une hypothèse est faite sur la forme de la loi de distribution, et dans le second, sur les paramètres de deux distributions. Les hypothèses basées sur lesquelles il n'y a pas d'hypothèses sur un type spécifique de loi de distribution sont appelées non paramétrique, Par ailleurs - paramétrique.
L'hypothèse qu'il n'y a pas de différence entre les caractéristiques comparées, et que les écarts observés ne s'expliquent que par des fluctuations aléatoires des échantillons sur la base desquels la comparaison est faite, est appelée nul(principale) hypothèse et dénotent H 0 . Parallèlement à l'hypothèse principale, nous considérons également alternative(concurrencer, contredire) son hypothèse H une . Et si l'hypothèse nulle est rejetée, alors l'hypothèse alternative aura lieu.
Distinguer les hypothèses simples des hypothèses complexes. L'hypothèse s'appelle Facile, s'il caractérise de manière unique le paramètre de distribution de la variable aléatoire. Par exemple, si est un paramètre d'une distribution exponentielle, alors l'hypothèse H 0 sur l'égalité = 10 est une hypothèse simple. complexe appelée une hypothèse qui consiste en un ensemble fini ou infini d'hypothèses simples. Hypothèse complexe H 0 sur les inégalités > 10 consiste en un nombre infini d'hypothèses simples H 0 sur l'égalité =b je, où b je- tout nombre supérieur à 10. Hypothèse H 0 que l'espérance d'une distribution normale est de deux pour une variance inconnue est également délicate. Une hypothèse complexe sera l'hypothèse sur la distribution d'une variable aléatoire X selon la loi normale, si des valeurs spécifiques de l'espérance mathématique et de la variance ne sont pas fixes.
Le test d'hypothèse est basé sur le calcul d'une variable aléatoire - un critère dont la distribution exacte ou approximative est connue. Notons cette quantité par z, sa valeur est fonction des éléments de l'échantillon z=z(x 1 , x 2 , …, x n). La procédure de test d'hypothèse prescrit à chaque valeur de critère l'une des deux décisions - accepter ou rejeter l'hypothèse. Ainsi, tout l'espace d'échantillonnage et, par conséquent, l'ensemble des valeurs de critère sont divisés en deux sous-ensembles non superposés S 0 et S une . Si la valeur du critère z tombe dans la zone S 0 , alors l'hypothèse est acceptée, et si S 1 , – l'hypothèse est rejetée. Beaucoup de S 0 s'appelle zone d'acceptation de l'hypothèse ou zone de valeurs acceptables, et l'ensemble S 1 – zone de rejet d'hypothèse ou zone critique. Le choix d'un domaine détermine uniquement l'autre domaine.
Acceptation ou rejet de l'hypothèse H 0 selon un échantillon aléatoire correspond à la vérité avec une certaine probabilité et, par conséquent, deux types d'erreurs sont possibles. Une erreur de type I se produit avec la probabilité lorsque l'hypothèse correcte est rejetée. H 0 et l'hypothèse concurrente est acceptée H une . Une erreur de seconde espèce se produit avec probabilité dans le cas où une hypothèse incorrecte est acceptée H 0 , alors que l'hypothèse concurrente est vraie H 1 . Probabilité de confiance est la probabilité de ne pas commettre d'erreur de type I et d'accepter la bonne hypothèse H 0 . Probabilité de rejeter une fausse hypothèse H 0 s'appelle la puissance du critère. Par conséquent, lors du test de l'hypothèse, il existe quatre résultats possibles, Tableau. 3.1.
Tableau 3.1.
Par exemple, considérons le cas où une estimation non biaisée du paramètre est calculée à partir d'un échantillon de volume n, et cette estimation a une densité de distribution F(), fig. 3.1.

Riz. 3.1. Domaines et déviations de l'hypothèse
Supposons que la vraie valeur du paramètre estimé est égale à J. Si l'on considère l'hypothèse H 0 sur l'égalité = J, alors quelle devrait être la différence entre et J rejeter cette hypothèse. On peut répondre à cette question dans un sens statistique, compte tenu de la probabilité d'atteindre une différence donnée entre et J basée sur la distribution d'échantillonnage du paramètre .
Il convient de prendre les mêmes valeurs de la probabilité que le paramètre dépasse les limites inférieure et supérieure de l'intervalle. Une telle hypothèse permet dans de nombreux cas de minimiser l'intervalle de confiance, c'est-à-dire augmenter la puissance du critère de test. La probabilité totale que le paramètre aille au-delà de l'intervalle avec les limites 1– /2 et /2 est . Cette valeur doit être choisie si petite qu'il est peu probable qu'elle dépasse l'intervalle. Si l'estimation du paramètre tombe dans un intervalle donné, alors dans ce cas il n'y a aucune raison de remettre en question l'hypothèse testée, donc l'hypothèse d'égalité = J peut être accepté. Mais si, après réception de l'échantillon, il s'avère que l'estimation est en dehors des limites établies, alors dans ce cas, il y a de sérieuses raisons de rejeter l'hypothèse H 0 . Il s'ensuit que la probabilité de commettre une erreur de type I est égale à (égal au seuil de signification du critère).
En supposant, par exemple, que la vraie valeur du paramètre est en fait égale à J+ré, alors selon l'hypothèse H 0 sur l'égalité = J– la probabilité que l'estimation du paramètre tombe dans la zone d'acceptation de l'hypothèse sera , fig. 3.2.

Pour une taille d'échantillon donnée, la probabilité de commettre une erreur de type I peut être réduite en abaissant le seuil de signification . Cependant, dans ce cas, la probabilité d'une erreur de seconde espèce augmente (la puissance du critère diminue). Un raisonnement similaire peut être effectué pour le cas où la vraie valeur du paramètre est égale à J– ré.
La seule façon de réduire les deux probabilités est d'augmenter la taille de l'échantillon (la densité de distribution de l'estimation des paramètres devient plus "étroite"). Lors du choix d'une région critique, ils sont guidés par la règle de Neumann-Pearson : il faut choisir une région critique de manière à ce que la probabilité soit petite si l'hypothèse est vraie, et grande sinon. Cependant, le choix d'une valeur particulière de est relativement arbitraire. Les valeurs communes vont de 0,001 à 0,2. Afin de simplifier calculs manuels des tableaux d'intervalles avec des limites 1– /2 et /2 pour des valeurs typiques de et diverses méthodes de construction du critère ont été compilés.
Lors du choix d'un niveau de signification, il est nécessaire de prendre en compte la puissance du critère sous une hypothèse alternative. Parfois, une grande puissance du critère s'avère plus significative qu'un petit niveau de signification, et sa valeur est choisie relativement grande, par exemple 0,2. Un tel choix est justifié si les conséquences des erreurs du deuxième type sont plus importantes que les erreurs du premier type. Par exemple, en cas de rejet la bonne décision"continuer les utilisateurs avec les mots de passe actuels", alors le premier type d'erreur entraînera un certain retard dans le fonctionnement normal du système associé à la modification des mots de passe. S'il est décidé de ne pas modifier les mots de passe, malgré le danger d'accès non autorisé aux informations par des personnes non autorisées, cette erreur entraînera des conséquences plus graves.
Selon la nature de l'hypothèse testée et les mesures d'écart entre l'évaluation d'une caractéristique et sa valeur théorique, divers critères sont utilisés. Les critères les plus couramment utilisés pour tester les hypothèses sur les lois de distribution comprennent les tests du chi carré de Pearson, Kolmogorov, Mises, Wilcoxon et les tests de Fisher et Student pour les valeurs des paramètres.
25. ZONE CRITIQUE- une partie de l'espace de l'échantillon telle que l'entrée dans celui-ci de la valeur observée d'une variable aléatoire, à la distribution de laquelle l'hypothèse testée est associée, entraîne le rejet de cette hypothèse
points critiques(les frontières) k cr sont les points séparant la région critique de la région d'acceptation de l'hypothèse.
Il existe des régions critiques unilatérales (côté droit ou gauche) et bilatérales.
L'erreur de mesure aléatoire se forme sous l'influence d'un grand nombre de facteurs accompagnant le processus de mesure. Dans chaque situation particulière exploite son propre mécanisme d'erreur. Par conséquent, il est naturel de supposer que chaque situation doit avoir son propre type de distribution d'erreurs. Cependant, dans de nombreux cas, il est possible de faire certaines hypothèses sur la forme de la fonction de distribution avant même les mesures, de sorte qu'après les mesures, il ne reste plus qu'à déterminer les valeurs de certains paramètres qui sont inclus dans l'expression de l'estimation fonction de répartition.
L'erreur aléatoire caractérise l'incertitude de nos connaissances sur la valeur réelle de la valeur mesurée, obtenue à la suite des observations. Selon K. Shannon, la mesure de l'incertitude de la situation, décrite Variable aléatoire X, est l'entropie

qui est une fonctionnelle de la fonction de distribution différentielle . On peut supposer que tout processus de mesure est formé de telle manière que l'incertitude du résultat d'observation s'avère être la plus grande dans certaines limites déterminées par les valeurs d'erreur tolérées. Par conséquent, les plus probables devraient être de telles distributions dans lesquelles l'entropie atteint un maximum.
Pour identifier le type des distributions les plus probables, considérons quelques-uns des cas les plus typiques.
1. Dans la classe des distributions des résultats d'observation, qui ont une certaine zone de dispersion entre les valeurs x = b et X = un largeur b-a=2a, trouvez-en un qui maximise l'entropie  en présence de conditions limites :
en présence de conditions limites :
,  , ,
, ,
où est l'espérance mathématique des résultats d'observation. La solution du problème est trouvée par la méthode des multiplicateurs de Lagrange.
La densité de distribution souhaitée des résultats des observations est décrite par l'expression
Définissons les caractéristiques numériques de la distribution uniforme. L'espérance mathématique d'une erreur aléatoire est trouvée par la formule (10):
La dispersion d'une erreur aléatoire uniformément distribuée peut être trouvée par la formule (18):

En raison de la symétrie de la distribution par rapport à l'espérance mathématique, le coefficient d'asymétrie doit être égal à zéro :
Pour déterminer le kurtosis, nous trouvons d'abord le quatrième moment de l'erreur aléatoire :

C'est pourquoi ![]()
En conclusion, nous trouvons la probabilité qu'une erreur aléatoire tombe dans un intervalle donné égal à la zone ombrée de la Fig. 7 

2. Dans la classe des distributions de résultats d'observation avec une certaine variance , on en trouve une qui maximise l'entropie  s'il y a des restrictions :
s'il y a des restrictions :
,  ,
,  ,
,  .
.
La solution de ce problème est également trouvée par la méthode des multiplicateurs de Lagrange. La densité de distribution souhaitée des résultats des observations est décrite par l'expression
La distribution décrite par les équations (25) et (26) est appelée Ordinaire ou Distribution gaussienne.
La figure 8 montre les courbes de la distribution normale des erreurs aléatoires pour différentes significationsécart-type ![]() .
.
On peut voir sur la figure qu'à mesure que l'écart type augmente, la distribution s'étend de plus en plus, la probabilité d'occurrence grandes valeurs les erreurs augmentent et la probabilité d'erreurs plus petites diminue, c'est-à-dire la dispersion des résultats d'observation augmente.
Calculons la probabilité que le résultat de l'observation tombe dans un intervalle donné :
Changeons les variables :
![]()
On obtient alors l'expression suivante pour la probabilité recherchée :
Les intégrales entre crochets ne sont pas exprimées en fonctions élémentaires, elles sont donc calculées en utilisant la loi dite normale normalisée avec une fonction différentielle
A l'aide de la fonction F( z) la probabilité est trouvée comme
| (29) |
Lors de l'utilisation de cette formule, il faut garder à l'esprit l'identité
![]()
Découlant directement de la définition de la fonction Ф( z).
La large distribution de la distribution normale des erreurs dans la pratique de la mesure s'explique par le théorème central limite de la théorie des probabilités, qui est l'un des théorèmes mathématiques les plus remarquables, au développement duquel de nombreux mathématiciens éminents ont participé - De Moivre, Laplace, Gauss , Tchebychev et Lyapunov. Théorème central limite stipule que la distribution des erreurs aléatoires sera proche de la normale chaque fois que les résultats d'une observation sont formés sous l'influence d'un grand nombre de facteurs agissant indépendamment, chacun d'eux n'ayant qu'un faible effet par rapport à l'effet total de tous les autres.
3. Supposons que les résultats des observations sont normalement distribués, mais que leur écart type est une valeur aléatoire qui varie d'une expérience à l'autre. Cette hypothèse est plus prudente que l'hypothèse d'invariance pendant tout le temps de mesure. Dans ce cas, en raisonnant de la même manière que précédemment, il est facile de trouver que l'entropie est maximisée si les résultats des observations ont une distribution de Laplace de densité
 | (30) |
où est l'espérance mathématique, est l'écart type des résultats d'observation. La distribution de Laplace doit être utilisée dans les cas où les caractéristiques de précision ne sont pas connues à l'avance ou sont instables dans le temps.
Fonction différentielle distribution des erreurs aléatoires est obtenue en substituant et dans l'expression (30) :
L'asymétrie de distribution est égale à zéro, puisque la distribution est symétrique autour de zéro, et l'aplatissement, conformément à la formule (22), est
Ainsi, par rapport à la distribution normale ( Ex= 0) la distribution uniforme est plus plate ( Ex= -1.2), et la distribution de Laplace est plus pointue ( Ex = 3).
Formes de présentation des données statistiques.
Les données statistiques doivent être présentées de manière à pouvoir être utilisées. Il y a 3 principaux formes de présentation des données statistiques:
Texte - inclusion de données dans le texte ;
Tabulaire - présentation des données dans des tableaux ;
Graphique - l'expression de données sous forme de graphiques.
Forme de texte utilisé avec une petite quantité de données numériques.
forme tabulaire est le plus souvent utilisé, car il s'agit d'une forme plus efficace de présentation des données statistiques. Contrairement aux tables mathématiques qui, selon les conditions initiales, permettent d'obtenir tel ou tel résultat, les tables statistiques racontent le langage des nombres sur les objets étudiés.
Tableau statistique- il s'agit d'un système de lignes et de colonnes, dans lequel les informations statistiques sur les phénomènes socio-économiques sont présentées dans une certaine séquence et connexion.
Distinguer le sujet et le prédicat du tableau statistique. Le sujet indique l'objet caractérisé - soit des unités de la population, soit des groupes d'unités, soit la totalité dans son ensemble. Dans le prédicat, la caractéristique du sujet est donnée, généralement sous forme numérique. L'en-tête du tableau est obligatoire, ce qui indique à quelle catégorie et à quelle heure appartiennent les données du tableau.
Selon la nature du sujet, les tableaux statistiques sont divisés en tableaux simples, groupés et combinés. Dans le sujet d'un tableau simple, l'objet d'étude n'est pas divisé en groupes, mais soit une liste de toutes les unités de la population est donnée, soit la population dans son ensemble est indiquée. Dans le sujet du tableau de groupe, l'objet d'étude est divisé en groupes selon un attribut, et le prédicat indique le nombre d'unités dans les groupes (absolu ou en pourcentage) et des indicateurs récapitulatifs pour les groupes. Dans le sujet du tableau de combinaison, la population est divisée en groupes non pas selon un, mais selon plusieurs critères.
Lors de la construction de tableaux, les règles générales suivantes doivent être suivies.
Le sujet du tableau est situé dans la partie gauche (rarement - supérieure) et le prédicat - dans la partie droite (moins souvent - inférieure).
Les en-têtes de colonnes contiennent les noms des indicateurs et leurs unités de mesure.
La dernière ligne complète le tableau et se situe à son extrémité, mais il s'agit parfois de la première : dans ce cas, la deuxième ligne s'écrit « y compris », et les lignes suivantes contiennent les composantes de la ligne totale.
Les données numériques sont écrites avec le même degré de précision dans chaque colonne, avec les chiffres des nombres situés sous les chiffres, et la partie entière est séparée de la virgule fractionnaire.
Le tableau ne doit pas contenir de cellules vides : si les données sont nulles, le signe "-" (tiret) est mis ; si les données ne sont pas connues, l'entrée «aucune information» est faite ou le signe «…» (points de suspension) est mis. Si la valeur de l'exposant n'est pas zéro, mais que le premier chiffre significatif apparaît après le degré de précision accepté, alors 0,0 est enregistré (si, par exemple, un degré de précision de 0,1 a été accepté).
Parfois, les tableaux statistiques sont complétés par des graphiques lorsque le but est de mettre en évidence certaines caractéristiques des données, de les comparer. La forme graphique est la forme la plus efficace de présentation des données en termes de perception. À l'aide de graphiques, la visibilité des caractéristiques de la structure, de la dynamique, de la relation des phénomènes et de leur comparaison est obtenue.
Molchanov Sergueï
Les statistiques savent tout », ont déclaré Ilf et Petrov dans leur célèbre roman « Les douze chaises » et ont poursuivi : « On sait combien de nourriture le citoyen moyen de la république mange par an… On sait combien de chasseurs, de ballerines… . machines, bicyclettes dans le pays , monuments, phares et machines à coudre ... Combien de vie, pleine d'ardeur, de passions et de pensées, nous regarde à partir de tableaux statistiques! .. ”Pourquoi ces tableaux sont-ils nécessaires, comment compiler et traiter eux, quelles conclusions peuvent être tirées sur leur base - les statistiques répondent à ces questions (de l'italien stato - état, statut latin - état).La statistique est une science qui étudie, traite et analyse des données quantitatives sur une grande variété de phénomènes de masse dans la vie.
Objectifs du travail : Se faire une idée de la recherche statistique, du traitement des données et de l'interprétation des résultats.
Télécharger:
Aperçu:
«Les statistiques savent tout», ont déclaré Ilf et Petrov dans leur célèbre roman «Les douze chaises» et ont poursuivi: «On sait combien de nourriture le citoyen moyen de la république mange par an ... On sait combien de chasseurs, de ballerines. .. machines-outils, vélos, monuments, phares et machines à coudre ... Combien de vie, pleine d'ardeur, de passions et de pensées, nous regarde à partir de tableaux statistiques! .. "Pourquoi ces tableaux sont-ils nécessaires, comment les compiler et les traiter , quelles conclusions peut-on en tirer - ces questions sont répondues par des statistiques (de l'italien stato - état, statut latin - état).
La statistique est une science qui étudie, traite et analyse des données quantitatives sur une grande variété de phénomènes de masse dans la vie.
Objectifs du travail :
Se faire une idée de la recherche statistique, du traitement des données et de l'interprétation des résultats.
Collecte d'informations statistiques, traitement et analyse des résultats du point de vue que l'enseignement des mathématiques est un élément nécessaire du développement.
Tâches de travail:
Créer une image visuelle de l'enseignement des mathématiques en classe.
Se faire une idée de la possibilité de décrire et de traiter des données à l'aide de diverses caractéristiques statistiques.
Gestion et prévision du développement ultérieur de l'enseignement des mathématiques.
Hypothèse. Les statistiques nous permettent d'identifier les problèmes de l'enseignement des mathématiques dans notre classe.
Pertinence : Augmenter la motivation dans l'enseignement des sciences mathématiques, lien avec des situation de vie. La capacité de collecter, traiter et analyser des données statistiques lors de la travail de recherche.
Planifier:
Introduction:
Histoire du développement des statistiques.
Caractéristiques statistiques.
II. Travail de recherche:
Questionnaire.
Tableau de toutes les données.
Diagrammes et conclusions (gammes, modes, fréquences, polygones de fréquence, moyenne arithmétique).
Conclusion générale :.
Histoire des statistiques.
Les statistiques ont une longue histoire. Déjà dans la période ancienne de l'histoire humaine, les besoins économiques et militaires nécessitaient la disponibilité de données sur la population, sa composition et son statut foncier. Aux fins de la fiscalité, des recensements de la population ont été organisés, des registres fonciers ont été établis.
La première publication sur les statistiques est le "Livre des Nombres" dans la Bible, dans l'Ancien Testament, qui relate le recensement des assujettis au service militaire effectué sous la direction de Moïse et d'Aaron.
Pour la première fois, on retrouve le terme "statistiques" dans la fiction - dans "Hamlet" de Shakespeare (1602, acte 5, scène 2). Le sens de ce mot dans Shakespeare est de savoir, courtisans.
Initialement, les statistiques étaient comprises comme des descriptions de l'état économique et politique d'un État ou d'une partie de celui-ci. Par exemple, la définition fait référence à 1792 : "des statistiques décrivant l'état de l'état à l'heure actuelle ou à un moment connu dans le passé". À l'heure actuelle, les activités des services statistiques de l'État correspondent bien à cette définition.
Peu à peu, cependant, le terme "statistiques" a commencé à être utilisé plus largement. Selon Napoléon Bonaparte, "les statistiques sont le budget des choses". Selon le libellé de 1833 "Le but des statistiques est de présenter les faits sous la forme la plus concise."
Voici deux autres déclarations.
La statistique consiste dans l'observation de phénomènes qui peuvent être, subordonnés ou exprimés au moyen de nombres (1895).
Les statistiques sont une représentation numérique des faits de n'importe quel domaine d'étude dans leur relation.
Au fil du temps, la collecte de données sur les phénomènes sociaux de masse a acquis un caractère régulier.
A partir du milieu du XIXème siècle. grâce aux efforts du grand mathématicien, astronome et statisticien belge Adolphe Quetelet (1796-1874), des règles pour les recensements de population ont été élaborées et la régularité de leur déroulement dans les pays développés a été établie. Pour coordonner le développement de la statistique, à l'initiative d'A. Quetelet, des congrès internationaux de statistique sont organisés et en 1885 est fondé l'Institut international de statistique, qui existe encore aujourd'hui.
La formation des statistiques d'État en Russie peut être attribuée à la fin du XIIe - début du XIIIe siècle, bien que les premiers recensements de la terre et de la population avec un programme de plus en plus complexe aient été effectués en Rus de Kiev(IX - XII siècles). Les réformes de Pierre Ier (1672-1725), qui couvraient tous les principaux domaines de la vie publique : l'économie du pays, l'administration, l'armée, la culture et la vie de la population, ainsi que les guerres, ont entraîné la nécessité d'une comptabilité complète et précise des ressources matérielles et de la population. Au cours de cette période, l'organe gouvernemental le plus élevé - le Sénat - à travers le système de conseils, non seulement gérait l'économie du pays, mais était également le centre d'exécution des travaux statistiques les plus importants, il y avait des matériaux d'enquête collectés, des rapports des industries et des institutions subordonnées aux conseils, ainsi qu'à l'administration locale.
La réforme Petrovsky du système fiscal est associée à l'émergence d'une nouvelle unité, elle est devenue «l'âme» du mâle, ce qui a nécessité un recensement par habitant - révision. La première révision a été annoncée le 26 novembre 1718, la révision a été effectuée par l'armée.
Au début du XIIIe siècle. En Russie, le compte courant de la population est également né. Ainsi, en 1702, un décret fut publié sur la soumission à l'Ordre Spirituel Patriarcal par les curés des rapports hebdomadaires des naissances et des décès. Dans la première moitié du XIIIe siècle. il y avait déjà des recensements des ouvriers dans les usines et les manufactures.
Première moitié du XIXe siècle associée à une nouvelle étape dans le développement des statistiques nationales. En septembre 1802, conformément au Manifeste suprême de l'empereur Alexandre Ier, des rapports écrits sur les ministères ont été introduits. Ainsi a commencé la conception opérationnelle et structurelle des statistiques d'État en Russie. Cette année est considérée comme l'année de naissance des statistiques de l'État russe.
En 1811, pour la première fois, un centre officiel de statistiques gouvernementales a été créé - le Département des statistiques relevant du ministère de l'Intérieur; voici venir les rapports des provinces. Le premier chef de la Division des statistiques était K.F. Herman.
Les scientifiques russes ont apporté une grande contribution au développement de la science statistique. D'une grande importance, par exemple, est le travail de D.P. Zhuravsky "Sur les sources et l'utilisation des informations statistiques", publié en 1846. Définissant les statistiques comme "comptage par catégories", Zhuravsky a noté que les statistiques sont nécessaires pour "l'étude de tout ce qui concerne une personne". Zhuravsky a identifié les sections les plus importantes des statistiques sociales :
statistiques démographiques - la nécessité de les calculer par classe et profession;
l'étude de la vie populaire, du logement, de la nutrition ;
statistiques des théâtres, des clubs, des réunions de la noblesse, des divertissements publics ;
statistiques des institutions protégeant les droits de propriété;
statistiques de la pauvreté, de la pauvreté, des orphelins;
des statistiques sur les suicides indiquant les moyens, les causes, les rangs, l'âge et d'autres caractéristiques des personnes qui se sont suicidées.
Dans tous les D.P. Zhuravsky a poursuivi l'idée de révéler aussi précisément et complètement que possible la différenciation des personnes selon les conditions de leur vie, selon leur richesse.
Une place particulière dans l'histoire des statistiques russes appartient aux statistiques de Zemstvo. Sous les zemstvos, les gouvernements locaux, à partir du milieu des années 70 du XIXe siècle, des bureaux statistiques spéciaux ont été créés. Les statisticiens de Zemstvo ont collecté et développé un vaste matériel statistique, qui a été utilisé pour des études économiques et sociales approfondies de la Russie post-réforme. Le travail des statistiques zemstvo se caractérise non seulement par la collecte et le développement de données statistiques, mais également par le développement de la méthodologie statistique.
Les statisticiens zemstvo éminents étaient V.I. Orlov, P.P. Chervinsky, FA. Shcherbina, A.P. Chlikévitch.
Dans les années 1990, des inspections du travail ont été créées qui tenaient des statistiques à jour, développaient des données sur les statistiques du travail, y compris la composition de la main-d'œuvre, les accidents, les grèves, etc.
Les statistiques industrielles ont commencé à se développer. Sous la direction de V.E. Varzara en 1900, 1908 et 1912 Les premiers recensements de l'industrie sont réalisés.
La première étape de la statistique soviétique (1917-1930) est exceptionnellement intense : grand nombre spécialement organisé, statistique
recensements et enquêtes, diverses équipes de recherche travaillent fructueusement, le premier bilan se construit économie nationale.
Le développement ultérieur des statistiques soviétiques a été entravé par la création d'un système administratif et bureaucratique dans les années 30, des répressions de masse, y compris les meilleurs économistes et statisticiens (N.D. Kondratiev, A.V. Chayanov, V.G. Groman, O.A. Kvitnin et bien d'autres).
À l'heure actuelle, des statistiques sectorielles sont en cours de formation, un système d'indicateurs volumétriques est en cours de formation, masquant les tendances négatives du développement de l'économie nationale. Des indicateurs statistiques qualitatifs (indices de productivité du travail, prime cost, etc.) sont également activement développés. La statistique est soumise à la solution des tâches opérationnelles, à l'évaluation de la mise en œuvre du plan au détriment de ses fonctions analytiques.
Pendant les années du Grand Guerre patriotique Les statistiques soviétiques étaient confrontées à la tâche de comptabilisation opérationnelle des ressources en main-d'œuvre et en matériel, le transfert des forces productives du pays vers les régions orientales.
Après la guerre, le rôle et l'importance de la statistique s'accroissent : les travaux d'équilibre se développent, la théorie de la méthode indicielle s'approfondit et la pratique de son application s'élargit, les modèles et méthodes économiques et mathématiques se généralisent et la statistique appliquée se développe.
Le mot "statistiques" est souvent associé au mot "mathématiques", ce qui effraie les élèves qui associent ce concept à formules complexes exigeant haut niveau abstraction.
Cependant, comme le dit McConnell, les statistiques sont avant tout une façon de penser, et pour les utiliser, il suffit d'avoir un peu bon sens et connaître les bases des mathématiques. Dans notre Vie courante nous, sans nous en rendre compte, sommes constamment engagés dans des statistiques. Voulons-nous planifier un budget, calculer la consommation d'essence d'une voiture, estimer l'effort qui sera nécessaire pour maîtriser un certain parcours, en tenant compte des notes obtenues jusqu'à présent, prédire la probabilité du beau et du mauvais temps à partir d'un bulletin météo , ou généralement estimer comment tel ou tel événement affectera notre avenir personnel ou collectif - nous devons constamment sélectionner, classer et organiser les informations, les relier à d'autres données afin de pouvoir en tirer des conclusions qui nous permettent de prendre la bonne décision.
Toutes ces activités diffèrent peu des opérations qui sous-tendent la recherche scientifique et consistent en la synthèse de données obtenues sur divers groupes d'objets dans une expérience particulière, en leur comparaison afin de découvrir les différences entre eux, en leur comparaison afin d'identifier des indicateurs qui évoluent dans un sens, et, enfin, dans la prédiction de certains faits à partir des conclusions auxquelles conduisent les résultats. C'est précisément le but de la statistique dans les sciences en général, en particulier dans les sciences humaines. Il n'y a rien d'absolument fiable dans ce dernier, et sans statistiques, les conclusions seraient dans la plupart des cas purement intuitives et ne pourraient pas constituer une base solide pour interpréter les données obtenues dans d'autres études.
Afin d'apprécier les énormes avantages que peuvent apporter les statistiques, nous essaierons de suivre les progrès du déchiffrement et du traitement des données obtenues dans l'expérience. Ainsi, à partir des résultats précis et des questions qu'ils posent au chercheur, nous pourrons comprendre les différentes méthodes et les façons simples de les appliquer. Cependant, avant de nous lancer dans ce travail, il nous sera utile de considérer au plus de façon générale trois sections principales de statistiques.
1. La statistique descriptive, comme son nom l'indique, permet de décrire, résumer et reproduire sous forme de tableaux ou de graphiques
2. La tâche des statistiques inductives est de vérifier si les résultats obtenus sur un échantillon donné peuvent être étendus à l'ensemble de la population dont cet échantillon est issu. En d'autres termes, les règles de cette section de statistiques permettent de savoir dans quelle mesure il est possible, par induction, de généraliser à un plus grand nombre d'objets telle ou telle régularité découverte en étudiant leur groupe restreint au cours de n'importe quel observation ou expérience. Ainsi, à l'aide de statistiques inductives, certaines conclusions et généralisations sont faites sur la base des données obtenues lors de l'étude de l'échantillon.
3. Enfin, la mesure de la corrélation nous permet de savoir dans quelle mesure deux variables sont liées, de sorte que nous pouvons prédire les valeurs possibles de l'une d'entre elles si nous connaissons l'autre.
Il existe deux types de méthodes statistiques ou de tests qui permettent de généraliser ou de calculer le degré de corrélation. La première variété est la méthode paramétrique la plus largement utilisée, qui utilise des paramètres tels que la moyenne ou la variance des données. La deuxième variété est celle des méthodes non paramétriques, qui rendent un service inestimable lorsque le chercheur a affaire à de très petits échantillons ou à des données qualitatives ; ces méthodes sont très simples en termes de calcul et d'application. Lorsque nous nous sommes familiarisés avec les différentes manières de décrire les données et que nous passons à leur analyses statistiques, nous considérerons ces deux variétés.
- Le mode est le numéro d'une série qui apparaît le plus souvent dans cette série. On peut dire que ce numéro est le plus "à la mode" de cette série.
- La moyenne arithmétique d'une série de nombres est le quotient de la division de la somme de ces nombres par leur nombre. La moyenne arithmétique est caractéristique importante série de chiffres, mais il est parfois utile de considérer d'autres moyennes
- L'un des indicateurs statistiques de la différence ou de la dispersion des données est la plage.
La plage est la différence entre les valeurs les plus grandes et les plus petites d'une série de données.
La médiane d'une série composée d'un nombre impair de nombres est le numéro d'une série donnée qui sera au milieu si cette série est triée. La médiane d'une série composée d'un nombre pair de nombres est la moyenne arithmétique des deux nombres au milieu de cette série.
Il existe un moyen plus pratique de trouver la moyenne arithmétique, ainsi que d'autres caractéristiques statistiques - en compilant un tableau de fréquences.
Types et méthodes d'observation statistique.
L'observation statistique diffère selon les types et les sources d'information.
Types d'observation statistique.
Observation systématique - actuelle : l'observation est effectuée sur la base de documents primaires contenant les informations nécessaires à une caractérisation assez complète du phénomène étudié.
Observation statistique - périodique. Un exemple est le recensement de la population.
Observation effectuée de temps en temps - une fois.
Les types d'observation statistique peuvent être continus et non continus.
La continue est une observation qui prend tout en compte sans qu'une seule unité de la population soit étudiée.
L'observation non continue est orientée vers la prise en compte d'une partie assez massive des unités d'observation.
Dans la pratique statistique, différentes sortes observation non continue :
sélectif;
méthode du tableau principal ;
questionnaire;
monographique.
La qualité de l'observation non continue est inférieure aux résultats de l'observation continue.
Pour obtenir une caractéristique représentative de l'ensemble de la population statistique pour une partie de ses unités, une observation d'échantillon est utilisée, basée sur les principes scientifiques de la formation d'une population d'échantillon. Le caractère aléatoire de la sélection des unités de la population garantit l'impartialité des résultats de l'échantillon.
Méthodes d'observation statistique.
Selon les sources des informations collectées, on distingue l'observation :
direct,
documentaire
interview.
L'observation directe est appelée, effectuée par comptage, mesure des valeurs des signes, prise de lectures d'instruments par des personnes spéciales qui effectuent des observations, en d'autres termes, par des greffiers.
L'observation documentaire est une telle observation lorsque la réponse aux questions du formulaire d'observation est enregistrée sur la base des documents pertinents.
Une enquête est une observation dans laquelle les réponses aux questions de la fiche d'observation sont enregistrées à partir des propos de l'enquêté.
Collecte et regroupement de données statistiques.
Pour étudier divers phénomènes sociaux et socio-économiques, ainsi que certains processus se produisant dans la nature, des études statistiques spéciales sont menées. Toute recherche statistique commence par une collecte ciblée d'informations sur le phénomène ou le processus à l'étude. Cette étape est appelée étape d'observation statistique.
Pour généraliser la systématisation des données obtenues au cours de l'observation statistique, elles sont divisées en groupes selon certains critères, et les résultats du regroupement sont résumés dans des tableaux.
Présentation visuelle des informations statistiques.
Pour une présentation visuelle des données obtenues à la suite d'une étude statistique, largement utilisée différentes manières leurs images.
L'un des moyens bien connus de visualiser une série de données consiste à créer un graphique à barres.
Les histogrammes sont utilisés lorsqu'ils veulent illustrer la dynamique des changements de données dans le temps ou la distribution des données obtenues en conséquence.
Pour une représentation visuelle de la relation entre les parties de la population étudiée, il est pratique d'utiliser des diagrammes circulaires.
Pour construire un camembert, le cercle est divisé en secteurs dont les angles au centre sont proportionnels aux fréquences relatives déterminées pour chaque groupe de données.
La dynamique des changements dans les données statistiques au fil du temps est souvent illustrée à l'aide d'un polygone. Pour construire un polygone, des points sont marqués dans le plan de coordonnées, dont les abscisses sont des points dans le temps, et les ordonnées sont les données statistiques correspondantes. En reliant ces points en série avec des segments, on obtient une ligne brisée, appelée polygone.
L'une des tâches principales de la statistique est précisément le bon traitement de l'information. Bien sûr, les statistiques ont bien d'autres tâches : obtenir et stocker des informations, faire diverses prévisions, évaluer leur fiabilité, etc. Aucun de ces objectifs ne peut être atteint sans traitement des données. Donc la première chose à faire est Méthodes statistiques traitement d'informations.
Dans notre classe, nous avons décidé de découvrir quel est le niveau de connaissances sur le sujet "Résolution de systèmes d'équations linéaires à deux variables", pour lequel nous avons fait un test spécial de six tâches
Dans la liste alphabétique des élèves, à côté de chaque nom de famille, le nombre de problèmes correctement résolus était inscrit. Le résultat est la suite de nombres suivante :
FI. | Nombre de tâches |
|
Agafonova L | ||
Bacharov un | ||
Guseletov D | ||
Darmaeva K | ||
Konevin V | ||
Korotkov V | ||
Krivolapova M | ||
Misyurkeev A | ||
Misyurkeev V | ||
Mineva D | ||
Mikhaïlov A | ||
Molchanova O | ||
Molchanov S | ||
Naumov S | ||
Popov avec | ||
Postnikova M | ||
Rekhovskaïa Yu | ||
Sataeva N. | ||
Terentyeva T | ||
Ouchakova L | ||
Chagdurova N | ||
Tolstikhine S | ||
Razouvaev A | ||
Angélique m |
Sur la base de cette série, il est difficile de tirer des conclusions définitives sur la façon dont le travail a été effectué. Pour faciliter l'analyse des informations, cas similaires les données numériques sont classées en les plaçant par ordre croissant. Suite au classement, la série prendra la forme suivante :
2; 2;
3; 3; 3; 3;
4; 4; 4; 4; 4; 4
5; 5; 5;5;5;5
6; 6; 6; 6;
On voit que la série est divisée en 6 groupes. Chaque groupe représente un certain résultat de l'expérience : un problème est résolu, deux problèmes sont résolus, etc.
Dans notre échantillon, la fréquence d'occurrence de l'événement « élève de cinquième a résolu un problème » est égale à 1. La fréquence relative de cet événement est égale au rapport de sa fréquence à la taille de l'échantillon, soit 1:23, soit 4,3 %. Pour l'événement « L'élève de troisième a résolu tous les problèmes », la fréquence est de 4, et la fréquence relative est de 4:23—, soit 17,4 %, etc.
Pour faciliter la perception des résultats, ils sont présentés sous forme de tableaux et de graphiques.
………
Après avoir compilé un tableau, il est utile de vérifier nous-mêmes : en additionnant toutes les fréquences, nous devrions obtenir la taille de l'échantillon, c'est-à-dire le nombre 50, et en additionnant toutes les fréquences relatives, nous devrions obtenir 100 %.
Pour une représentation graphique des données, nous allons construire un diagramme de fréquence basé sur ce tableau.
Avec l'aide du classement des séries, des tableaux et des illustrations graphiques, nous avons déjà reçu des informations initiales sur les modèles des séries de données qui nous intéressent. Mais vous connaissez les caractéristiques statistiques des séries de données qui vous permettent de faire une meilleure analyse statistique.
Ainsi, par exemple, il est intéressant de connaître le résultat le plus typique du travail proposé. En utilisant les données présentées dans le tableau, il est facile de voir que le résultat le plus courant est "trois problèmes résolus". Comme vous le savez, dans le langage des statistiques, cela signifie que le nombre 4 est le mode de cette série de nombres.
Il est également utile de trouver la moyenne arithmétique de cette série :
(1+2*2+3*4+4*6+5*6+6*4+:23=4.2Donc, on peut dire qu'en moyenne un élève de neuvième résout quatre problèmes. (Dans ce cas, la moyenne arithmétique de la série de données a coïncidé avec sa mode, mais, bien sûr, ce n'est pas toujours le cas.)
Étapes de la recherche statistique
Les étapes de la recherche statistique comprennent :
L'observation statistique est une collecte de masse scientifiquement organisée d'informations primaires sur des unités individuelles du phénomène à l'étude.
Regroupement et synthèse du matériel - généralisation des données d'observation pour obtenir des valeurs absolues (indicateurs comptables et estimés) du phénomène.
Traitement des données statistiques et analyse des résultats pour obtenir des conclusions raisonnables sur l'état du phénomène étudié et les schémas de son évolution.
Toutes les étapes de la recherche statistique sont étroitement liées les unes aux autres et ont la même importance. Les lacunes et les erreurs qui surviennent à chaque étape affectent l'ensemble de l'étude dans son ensemble. C'est pourquoi utilisation correcte des méthodes spéciales de science statistique à chaque étape vous permettent d'obtenir des informations fiables à la suite d'une recherche statistique.Méthodes de recherche statistique:
Observation statistique ;
Synthèse et regroupement des données ;
Calcul d'indicateurs généralisants (valeurs absolues, relatives et moyennes);
Distributions statistiques (séries de variations);
Méthode sélective ;
Analyse de corrélation et de régression ;
Rangées de dynamique ;
Index.
La statistique mathématique moderne est définie comme la science de la prise de décision dans l'incertitude. Il y a deux tâches principales statistiques mathématiques:
Préciser les méthodes de collecte et de regroupement des informations statistiques obtenues à la suite d'observations ou à la suite d'expériences.
Ainsi, la tâche des statistiques mathématiques est de créer des méthodes de collecte et de traitement des données statistiques pour obtenir des conclusions scientifiques et pratiques.
M Étapes du travail de recherche :
I. Collecte de données.
Comprend :
L'étude de la tâche.
Définition de concepts signifiants.
Sélection des sources d'information.
Collecte d'informations.
II. Regroupement de données.
Comprend :
Séparation des données en groupes par fonctionnalité.
Construire un tableau de données.
III. L'analyse des données.
Comprend :
Trouver des caractéristiques statistiques.
Généralisation des résultats obtenus.
IV. Signaler.
Nous avons mené une étude dans 7 classes "a" et "b" sur la nécessité d'étudier les mathématiques.
Collecte des données : Les élèves de l'école ont été invités à remplir un questionnaire. /Pièce jointe 1/
Regroupement des données : selon les données de l'enquête, un tableau a été compilé. /Annexe 2/
Analyse des données : les résultats du tableau ont été présentés sous forme de graphiques. /Annexe 3/
……
Les données traitées peuvent être utilisées :
Pour le travail des professeurs de classe avec la famille.
Pour application pratique en cours de maths..
Pour les chefs d'établissement.
Littérature:
Statistiques économiques. "Textbook", 2ème édition complétée. Recommandé par le ministère de l'Enseignement général et professionnel de la Fédération de Russie. Moscou. INFRA-M. 2006 Auteurs : Yu. N. Ivanov ; S. E. Kazarinova et autres. Sous la direction de Yu. N. Ivanov, docteur en économie.
ESB Édition informatique 2006
République des Komis en Russie. Goskomstat de Russie. Goskomstat R.K. 2007
Syktyvkar en chiffres. Goskomstat RK 2007
Note typique (mode) : 4Position 2. Loisirs étudiants
(Que font le plus souvent les enfants pendant leur temps libre après les cours)
Tableau d'enquête sociologique
Cours | Anglais | Jeux informatiques | Lire des livres | Regarder la télévision | Judo (section) | Volley-ball (section) | Marcher dans la rue |
Nombre d'étudiants | https://accounts.google.com Légendes des diapositives :c complété par: Molchanov Sergey 7 "B" Superviseur: Telesheva L.A. - professeur de mathématiques, MOU "Barguzinskaya sosh" Caractéristiques statistiques et recherche La statistique sait tout "Stato"-état "Statut"-état La statistique est une science qui étudie, traite et analyse des données quantitatives sur une grande variété de phénomènes de masse dans la vie. Se faire une idée de la recherche statistique, du traitement des données et de l'interprétation des résultats. Collecte d'informations statistiques, traitement et analyse des résultats d'un point de vue mathématique éducation - nécessaireélément de développement. but de l'étude: Créer une image visuelle de l'enseignement des mathématiques en classe. Se faire une idée de la possibilité de décrire et de traiter des données à l'aide de diverses caractéristiques statistiques. Gestion et prévision du développement ultérieur de l'enseignement des mathématiques. Les statistiques nous permettent d'identifier les problèmes de l'enseignement des mathématiques dans notre classe. Hypothèse : Accroître la motivation dans l'enseignement des sciences mathématiques ; lien avec des situations de vie spécifiques : capacité à collecter, traiter et analyser des données statistiques lors de la conduite de travaux de recherche. Pertinence Plan : Histoire des statistiques. Caractéristiques statistiques. Recherche sur le thème : « La nécessité des matières du cycle mathématique ». Recherche sur le sujet : " Passe-temps favori dans temps libre». La première publication sur les statistiques est le "Livre des Nombres" dans la Bible, dans l'Ancien Testament, qui raconte le recensement des conscrits effectué sous la direction de Moïse et d'Aaron. Pour la première fois, on retrouve le terme "statistiques" dans la fiction - dans "Hamlet" de Shakespeare (1602, acte 5, scène 2). Le sens de ce mot dans Shakespeare est de savoir, courtisans. la statistique est avant tout une façon de penser, et pour l'appliquer il suffit d'avoir un peu de bon sens et de connaître les bases des mathématiques. McConnell Sections statistiques corrélation inductive descriptive Principales caractéristiques statistiques Moyenne arithmétique Plage de modes Médiane La moyenne arithmétique d'une série de nombres est le quotient de la division de la somme de ces nombres par leur nombre. Le mode est généralement appelé le numéro d'une série qui apparaît le plus souvent dans cette série. La plage est la différence entre les valeurs les plus grandes et les plus petites d'une série de données. La médiane d'une série composée d'un nombre impair de nombres est le numéro d'une série donnée qui sera au milieu si cette série est triée. Types d'observation statistique Systématique Statistique (périodique) Ponctuelle Continue Non continue Non. F.I. Nombre de tâches correctement réalisées 1 Luda Agafonova 3 2 Andrey Basharov 6 3 Dima Guseletov 4 4 Ksenia Darmaeva 4 5 Vitaly Konevin 6 6 Volodia Korotkov 2 7 Masha Krivolapova 5 8 Alyosha Misyurkeev 3 9 Volodia Misyurkeev 3 10 Dasha Mineeva 5 11 Mikhailov A 5 12 Molchanova Olya 5 13 Molchanov S 6 14 Naumov P 6 15 Popov S 4 16 Postnikova M 4 17 Rekhovskaya Yulia 3 18 Sataeva Nastya 5 19 Terentyeva Tanya 5 20 Ushakova Lena 5 21 Chagdurova Natasha 4 22 Tolstikhin Andrey 1 23 Razuvaev Alyosha 2 24 Angelsky Misha 4 Résultat travail de contrôle sur le thème "Résolution de systèmes d'équations linéaires à deux variables" Considérons une série de nombres 3 6 4 4 6 2 5 3 3 5 5 5 6 6 4 4 3 5 5 5 4 1 2 4 Suite au classement, la série prendra la forme : 1 ; 2 ; 2 ; 3 ; 3 ; 3 ; 3 ; quatre ; quatre ; quatre ; quatre ; quatre ; 4 5 ; 5 ; 5;5;5;5 6; 6 ; 6 ; 6 ; Fréquence relative des événements Mode 4 Médiane 4 Plage 1 à 6 Moyenne arithmétique (1+2*2+3*4+4*6+5*4+6*4) :23=4,3 I. Collecte de données.: L'étude de la tâche. Définition de concepts signifiants. Sélection des sources d'information. Collecte d'informations. Analyse des données : les résultats du tableau ont été présentés sous forme de graphiques. II. Regroupement de données. Séparation des données en groupes par fonctionnalité. Construire un tableau de données. III. L'analyse des données. Trouver des caractéristiques statistiques. Généralisation des résultats obtenus. IV. Signaler. La nécessité d'étudier la recherche en mathématiques #1 Quelle matière scolaire aimes-tu le plus ? _________________- Quelle matière scolaire est facile à apprendre ? ______________________ Quelle est la matière la plus difficile à étudier ? __________________ Combien d'heures par jour consacres-tu à tes devoirs ?_____________________________________________________ Aimes-tu les maths ?_________________________________ As-tu besoin de maths à l'avenir ? ____________________________ Avez-vous besoin d'aide pour vos devoirs en mathématiques ? _______________________________________________________________ Comment évaluez-vous vos connaissances en mathématiques ? J'ai une note de ____________________ Je sais sur _______________________….. Je peux sur… ____________________________ Quelle est, à votre avis, la raison des échecs ou des échecs, s'ils se produisent ? Question 1 Quelle est votre matière scolaire préférée ? Question 2 Quelle est la matière scolaire la plus difficile à étudier ? Question 3 Combien de temps consacrez-vous à vos devoirs de mathématiques ? Question 4 Aimez-vous étudier les mathématiques ? Avez-vous besoin de mathématiques dans votre futur métier ? Oui -100% Avez-vous besoin d'aide pour vos devoirs de mathématiques Qui vous aide à comprendre un sujet difficile en mathématiques ? Maman -45% Enseignant-35% Manuel -20% Papa-15% Grand-mères10% Sœur-10% Amis-5% Personne-5% Comment évaluez-vous vos connaissances en mathématiques ? Vous voulez vous améliorer en maths ? Motivation de la recherche d'activités éducatives n ° 3 Type d'activité Tous les jours Plusieurs fois par semaine Le dimanche 1 Je lis des journaux et des magazines 2 Je lis fiction 5 Je vais à des soirées de loisirs 6 Je regarde des films 7 Je fais du sport 8 Je fais des travaux communautaires 9 Je chasse, pêche 11 Je fais de l'art amateur 12 Je fais de la randonnée 13 Je travaille à la radio 14 Je fais de la couture, des travaux d'aiguille 15 J'apprends à jouer d'un instrument de musique 16 J'écoute de la musique, je fais des disques 17 J'aime collectionner 18 J'aime danser, Je vais en discothèque 19 J'aime faire quelque chose de mes propres mains 20 Je joue avec les animaux 21 Pendant mon temps libre, j'aide mes parents 22 Je passe du temps sans but 23 Je travaille pendant mon temps libre 24 (Si tu es occupé à autre chose pendant ton temps libre, écris ici !) du quotidien Quelques fois par semaine Le dimanche Conclusion : Ainsi, les élèves de notre classe écoutent le plus souvent de la musique tous les jours, aident leurs parents, regardent la télévision ; plusieurs fois par semaine - faites du sport et faites quelque chose de vos mains; le dimanche - lire et jouer sur l'ordinateur, regarder la télévision Conclusion : Et donc, en utilisant l'exemple de mon travail de recherche, vous étiez convaincu que les caractéristiques statistiques et la recherche jouent un rôle important dans nos vies et sont utilisées non seulement en mathématiques, mais aussi dans d'autres branches de la science. Merci pour votre attention |
Les données statistiques doivent être présentées de manière à pouvoir être utilisées. Il existe 3 formes principales de présentation des données statistiques :
1) texte - l'inclusion de données dans le texte;
2) tabulaire - présentation des données dans des tableaux ;
3) graphique - l'expression de données sous forme de graphiques.
La forme texte est utilisée lorsqu'il y a une petite quantité de données numériques.
La forme tabulaire est utilisée le plus souvent, car il s'agit d'une forme plus efficace de présentation des données statistiques. Contrairement aux tables mathématiques qui, selon les conditions initiales, permettent d'obtenir tel ou tel résultat, les tables statistiques racontent le langage des nombres sur les objets étudiés.
Tableau statistique- il s'agit d'un système de lignes et de colonnes, dans lequel les informations statistiques sur les phénomènes socio-économiques sont présentées dans une certaine séquence et connexion.
Tableau 2. Commerce extérieur de la Fédération de Russie pour 2000 - 2006, milliards de dollars
| Indice | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 |
| Chiffre d'affaires du commerce extérieur | 149,9 | 155,6 | 168,3 | 280,6 | 368,9 | 468,4 | |
| Exporter | 101,9 | 107,3 | 135,9 | 183,2 | 243,6 | 304,5 | |
| Importer | 44,9 | 53,8 | 76,1 | 97,4 | 125,3 | 163,9 | |
| Balance commerciale | 60,1 | 48,1 | 46,3 | 59,9 | 85,8 | 118,3 | 140,7 |
| y compris: | |||||||
| avec des pays étrangers | |||||||
| exporter | 90,8 | 86,6 | 90,9 | 114,6 | 210,1 | 261,1 | |
| importer | 31,4 | 40,7 | 48,8 | 77,5 | 103,5 | 138,6 | |
| balance commerciale | 59,3 | 45,9 | 42,1 | 53,6 | 75,5 | 106,6 | 122,5 |
Par exemple, dans le tableau. 2 présente des informations sur le commerce extérieur de la Russie, qu'il serait inefficace d'exprimer sous forme textuelle.
Distinguer matière et prédicat tableau statistique. Le sujet indique l'objet caractérisé - soit des unités de la population, soit des groupes d'unités, soit la totalité dans son ensemble. Dans le prédicat, la caractéristique du sujet est donnée, généralement sous forme numérique. Obligatoire entête table, qui indique à quelle catégorie et à quelle heure appartiennent les données de la table.
Selon la nature du sujet, les tableaux statistiques sont divisés en Facile, groupe et combinatoire. Dans le sujet d'un tableau simple, l'objet d'étude n'est pas divisé en groupes, mais soit une liste de toutes les unités de la population est donnée, soit la population dans son ensemble est indiquée (par exemple, tableau 11). Dans le sujet du tableau de groupe, l'objet d'étude est divisé en groupes selon un attribut, et le prédicat indique le nombre d'unités dans les groupes (absolu ou en pourcentage) et des indicateurs récapitulatifs pour les groupes (par exemple, Tableau 4). Dans le sujet du tableau de combinaison, la population est divisée en groupes non pas selon un, mais selon plusieurs critères (par exemple, tableau 2).
Lors de la construction de tableaux, vous devez être guidé par les éléments suivants règles générales.
1. Le sujet du tableau est situé dans la partie gauche (moins souvent - supérieure) et le prédicat - dans la partie droite (moins souvent - inférieure).
2. Les en-têtes de colonne contiennent les noms des indicateurs et leurs unités.
3. La dernière ligne complète le tableau et se situe à son extrémité, mais parfois c'est la première : dans ce cas, la deuxième ligne est écrite « y compris », et les lignes suivantes contiennent les composants de la ligne totale.
4. Les données numériques sont écrites avec le même degré de précision dans chaque colonne, avec les chiffres des nombres situés sous les chiffres, et la partie entière est séparée de la virgule fractionnaire.
5. Il ne doit pas y avoir de cellules vides dans le tableau : si les données sont nulles, le signe "-" (tiret) est mis ; si les données ne sont pas connues, l'entrée «aucune information» est faite ou le signe «…» (points de suspension) est mis. Si la valeur de l'exposant n'est pas zéro, mais que le premier chiffre significatif apparaît après le degré de précision accepté, alors 0,0 est enregistré (si, par exemple, un degré de précision de 0,1 a été accepté).
Parfois, les tableaux statistiques sont complétés par des graphiques lorsque le but est de mettre en évidence certaines caractéristiques des données, de les comparer. La forme graphique est la forme la plus efficace de présentation des données en termes de perception. À l'aide de graphiques, la visibilité des caractéristiques de la structure, de la dynamique, de la relation des phénomènes et de leur comparaison est obtenue.
Graphiques statistiques- ce sont des images conditionnelles de valeurs numériques et de leurs rapports à travers des lignes, des formes géométriques, des dessins ou des cartes géographiques. La forme graphique facilite la prise en compte des données statistiques, les rend visuelles, expressives et visibles. Cependant, les graphiques ont certaines limites : tout d'abord, un graphique ne peut pas inclure autant de données qu'il peut contenir dans un tableau ; de plus, le graphique affiche toujours des données arrondies - pas exactes, mais approximatives. Ainsi, le graphique n'est utilisé que pour montrer la situation générale, pas les détails. Le dernier inconvénient est la complexité du tracé. Il peut être surmonté à l'aide d'un ordinateur personnel (par exemple, le "Diagram Wizard" du package Microsoft Office Excel).
Selon la méthode de construction des graphiques, ils sont divisés en diagrammes, cartogrammes et diagrammes graphiques.
Le moyen le plus courant de représentation graphique des données sont les graphiques, qui sont des types suivants : linéaire, radial, dispersé, planaire, volumétrique, bouclé. Le type de diagrammes dépend du type de données présentées et de la tâche de construction. Dans tous les cas, le graphique doit être accompagné d'un titre - au-dessus ou au-dessous du champ du graphique. Le titre indique quel indicateur est affiché, pour quel territoire et pour quelle heure.
Les graphiques linéaires sont utilisés pour représenter des variables quantitatives : caractéristiques de la variation de leurs valeurs, dynamique, relations entre variables. La variation des données est analysée à l'aide de zone de diffusion, cumule(inférieur à la courbe) et ogives(courbe "supérieur à"). Le polygone de distribution est discuté dans le Thème 4 (par exemple Fig. 5.). Pour construire un cumulé, les valeurs de la caractéristique variable sont tracées le long de l'abscisse, et les ordonnées sont les totaux cumulés des fréquences ou des fréquences (de f1à ∑ F). Pour construire une ogive, les totaux cumulés des fréquences sont placés sur l'axe des ordonnées dans l'ordre inverse (de ∑ F avant de f1). Cumulez et ogivez selon le tableau. 4. décrivez à la fig. une.
Riz. 1. Cumuls et ogives de la répartition des marchandises selon la valeur en douane
L'utilisation des graphiques linéaires dans l'analyse des tendances est traitée dans le Thème 5 (par exemple la Figure 13) et leur utilisation pour l'analyse des liens dans le Thème 6 (par exemple la Figure 21). Le sujet 6 couvre également l'utilisation des nuages de points (par exemple la figure 20).
Les graphiques linéaires sont subdivisés en unidimensionnel, utilisé pour représenter des données sur une seule variable, et bidimensionnel- pour deux variables. Un exemple de graphique linéaire unidimensionnel est un polygone de distribution, et un graphique bidimensionnel est une ligne de régression (par exemple, Fig. 21).
Parfois, avec de grands changements dans l'indicateur, une échelle logarithmique est utilisée. Par exemple, si les valeurs d'un indicateur varient de 1 à 1000, cela peut entraîner des difficultés lors du traçage. Dans de tels cas, ils passent aux logarithmes des valeurs de l'indicateur, qui ne différeront pas tellement : lg 1 = 0, lg 1000 = 3.
Parmi planaire Les graphiques à barres (histogrammes) se distinguent en fonction de la fréquence d'utilisation, dans lesquels l'indicateur est présenté sous la forme d'une barre dont la hauteur correspond à la valeur de l'indicateur (par exemple, Fig. 4).
La proportionnalité de l'aire d'une figure géométrique particulière à la valeur de l'indicateur sous-tend d'autres types de diagrammes planaires : triangulaire, carré, rectangulaire. Vous pouvez également utiliser une comparaison des aires d'un cercle - dans ce cas, le rayon du cercle est défini.
Bande dessinée présente des indicateurs sous la forme de rectangles étirés horizontalement, et est par ailleurs identique à un graphique à barres.
Parmi les diagrammes planaires, il est souvent utilisé diagramme circulaire, qui sert à illustrer la structure de la population étudiée. L'ensemble est pris à 100%, il correspond à l'aire totale du cercle, les aires des secteurs correspondent à des parties de l'ensemble. Construisons un diagramme sectoriel de la structure du commerce extérieur de la Fédération de Russie en 2006 selon le tableau. 2 (voir fig. 2). Lors de l'utilisation de programmes informatiques, les diagrammes de secteur sont construits sous forme tridimensionnelle, c'est-à-dire non pas sur deux, mais sur trois plans (voir Fig. 3).


Riz. 2. Graphique circulaire simple 3. Graphique circulaire 3D
Les diagrammes bouclés (image) améliorent la clarté de l'image, car ils incluent une image de l'indicateur affiché, dont la taille correspond à la taille de l'indicateur.
Lors du tracé d'un graphique, tout est également important - le bon choix d'une image graphique, les proportions, le respect des règles de conception des graphiques. Ces questions sont traitées plus en détail dans et.
Cartogrammes et cartogrammes sont utilisés pour représenter les caractéristiques géographiques des phénomènes étudiés. Ils montrent la localisation du phénomène étudié, son intensité sur un certain territoire - dans une république, une région, un district économique ou administratif, etc. La construction de cartogrammes et de cartogrammes est envisagée dans la littérature spécialisée, par exemple.
Les données statistiques doivent être présentées de manière à pouvoir être utilisées. Il existe 3 formes principales de présentation des données statistiques :
1) texte - l'inclusion de données dans le texte;
2) tabulaire - présentation des données dans des tableaux ;
3) graphique - l'expression de données sous forme de graphiques.
La forme texte est utilisée lorsqu'il y a une petite quantité de données numériques.
La forme tabulaire est utilisée le plus souvent, car il s'agit d'une forme plus efficace de présentation des données statistiques. Contrairement aux tables mathématiques qui, selon les conditions initiales, permettent d'obtenir tel ou tel résultat, les tables statistiques racontent le langage des nombres sur les objets étudiés.
Tableau statistique- il s'agit d'un système de lignes et de colonnes, dans lequel les informations statistiques sur les phénomènes socio-économiques sont présentées dans une certaine séquence et connexion.
Tableau 2. Commerce extérieur de la Fédération de Russie pour 2000 - 2006, milliards de dollars
| Indice | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 |
| Chiffre d'affaires du commerce extérieur | 149,9 | 155,6 | 168,3 | 280,6 | 368,9 | 468,4 | |
| Exporter | 101,9 | 107,3 | 135,9 | 183,2 | 243,6 | 304,5 | |
| Importer | 44,9 | 53,8 | 76,1 | 97,4 | 125,3 | 163,9 | |
| Balance commerciale | 60,1 | 48,1 | 46,3 | 59,9 | 85,8 | 118,3 | 140,7 |
| y compris: | |||||||
| avec des pays étrangers | |||||||
| exporter | 90,8 | 86,6 | 90,9 | 114,6 | 210,1 | 261,1 | |
| importer | 31,4 | 40,7 | 48,8 | 77,5 | 103,5 | 138,6 | |
| balance commerciale | 59,3 | 45,9 | 42,1 | 53,6 | 75,5 | 106,6 | 122,5 |
Par exemple, dans le tableau. 2 présente des informations sur le commerce extérieur de la Russie, qu'il serait inefficace d'exprimer sous forme textuelle.
Distinguer matière et prédicat tableau statistique. Le sujet indique l'objet caractérisé - soit des unités de la population, soit des groupes d'unités, soit la totalité dans son ensemble. Dans le prédicat, la caractéristique du sujet est donnée, généralement sous forme numérique. Obligatoire entête table, qui indique à quelle catégorie et à quelle heure appartiennent les données de la table.
Selon la nature du sujet, les tableaux statistiques sont divisés en Facile, groupe et combinatoire. Dans le sujet d'un tableau simple, l'objet d'étude n'est pas divisé en groupes, mais soit une liste de toutes les unités de la population est donnée, soit la population dans son ensemble est indiquée (par exemple, tableau 11). Dans le sujet du tableau de groupe, l'objet d'étude est divisé en groupes selon un attribut, et le prédicat indique le nombre d'unités dans les groupes (absolu ou en pourcentage) et des indicateurs récapitulatifs pour les groupes (par exemple, Tableau 4). Dans le sujet du tableau de combinaison, la population est divisée en groupes non pas selon un, mais selon plusieurs critères (par exemple, tableau 2).
Lors de la construction de tableaux, vous devez être guidé par les éléments suivants règles générales.
1. Le sujet du tableau est situé dans la partie gauche (moins souvent - supérieure) et le prédicat - dans la partie droite (moins souvent - inférieure).
2. Les en-têtes de colonne contiennent les noms des indicateurs et leurs unités.
3. La dernière ligne complète le tableau et se situe à son extrémité, mais parfois c'est la première : dans ce cas, la deuxième ligne est écrite « y compris », et les lignes suivantes contiennent les composants de la ligne totale.
4. Les données numériques sont écrites avec le même degré de précision dans chaque colonne, avec les chiffres des nombres situés sous les chiffres, et la partie entière est séparée de la virgule fractionnaire.
5. Il ne doit pas y avoir de cellules vides dans le tableau : si les données sont nulles, le signe "-" (tiret) est mis ; si les données ne sont pas connues, l'entrée «aucune information» est faite ou le signe «…» (points de suspension) est mis. Si la valeur de l'exposant n'est pas zéro, mais que le premier chiffre significatif apparaît après le degré de précision accepté, alors 0,0 est enregistré (si, par exemple, un degré de précision de 0,1 a été accepté).
Parfois, les tableaux statistiques sont complétés par des graphiques lorsque le but est de mettre en évidence certaines caractéristiques des données, de les comparer. La forme graphique est la forme la plus efficace de présentation des données en termes de perception. À l'aide de graphiques, la visibilité des caractéristiques de la structure, de la dynamique, de la relation des phénomènes et de leur comparaison est obtenue.
Graphiques statistiques- ce sont des images conditionnelles de valeurs numériques et de leurs rapports à travers des lignes, des formes géométriques, des dessins ou des cartes géographiques. La forme graphique facilite la prise en compte des données statistiques, les rend visuelles, expressives et visibles. Cependant, les graphiques ont certaines limites : tout d'abord, un graphique ne peut pas inclure autant de données qu'il peut contenir dans un tableau ; de plus, le graphique affiche toujours des données arrondies - pas exactes, mais approximatives. Ainsi, le graphique n'est utilisé que pour montrer la situation générale, pas les détails. Le dernier inconvénient est la complexité du tracé. Il peut être surmonté à l'aide d'un ordinateur personnel (par exemple, le "Diagram Wizard" du package Microsoft Office Excel).
Selon la méthode de construction des graphiques, ils sont divisés en diagrammes, cartogrammes et diagrammes graphiques.
Le moyen le plus courant de représentation graphique des données sont les graphiques, qui sont des types suivants : linéaire, radial, dispersé, planaire, volumétrique, bouclé. Le type de diagrammes dépend du type de données présentées et de la tâche de construction. Dans tous les cas, le graphique doit être accompagné d'un titre - au-dessus ou au-dessous du champ du graphique. Le titre indique quel indicateur est affiché, pour quel territoire et pour quelle heure.
Les graphiques linéaires sont utilisés pour représenter des variables quantitatives : caractéristiques de la variation de leurs valeurs, dynamique, relations entre variables. La variation des données est analysée à l'aide de zone de diffusion, cumule(inférieur à la courbe) et ogives(courbe "supérieur à"). Le polygone de distribution est discuté dans le Thème 4 (par exemple Fig. 5.). Pour construire un cumulé, les valeurs de la caractéristique variable sont tracées le long de l'abscisse, et les ordonnées sont les totaux cumulés des fréquences ou des fréquences (de f1à ∑ F). Pour construire une ogive, les totaux cumulés des fréquences sont placés sur l'axe des ordonnées dans l'ordre inverse (de ∑ F avant de f1). Cumulez et ogivez selon le tableau. 4. décrivez à la fig. une.
Riz. 1. Cumuls et ogives de la répartition des marchandises selon la valeur en douane
L'utilisation des graphiques linéaires dans l'analyse des tendances est traitée dans le Thème 5 (par exemple la Figure 13) et leur utilisation pour l'analyse des liens dans le Thème 6 (par exemple la Figure 21). Le sujet 6 couvre également l'utilisation des nuages de points (par exemple la figure 20).
Les graphiques linéaires sont subdivisés en unidimensionnel, utilisé pour représenter des données sur une seule variable, et bidimensionnel- pour deux variables. Un exemple de graphique linéaire unidimensionnel est un polygone de distribution, et un graphique bidimensionnel est une ligne de régression (par exemple, Fig. 21).
Parfois, avec de grands changements dans l'indicateur, une échelle logarithmique est utilisée. Par exemple, si les valeurs d'un indicateur varient de 1 à 1000, cela peut entraîner des difficultés lors du traçage. Dans de tels cas, ils passent aux logarithmes des valeurs de l'indicateur, qui ne différeront pas tellement : lg 1 = 0, lg 1000 = 3.
Parmi planaire Les graphiques à barres (histogrammes) se distinguent en fonction de la fréquence d'utilisation, dans lesquels l'indicateur est présenté sous la forme d'une barre dont la hauteur correspond à la valeur de l'indicateur (par exemple, Fig. 4).
La proportionnalité de l'aire d'une figure géométrique particulière à la valeur de l'indicateur sous-tend d'autres types de diagrammes planaires : triangulaire, carré, rectangulaire. Vous pouvez également utiliser une comparaison des aires d'un cercle - dans ce cas, le rayon du cercle est défini.
Bande dessinée présente des indicateurs sous la forme de rectangles étirés horizontalement, et est par ailleurs identique à un graphique à barres.
Parmi les diagrammes planaires, il est souvent utilisé diagramme circulaire, qui sert à illustrer la structure de la population étudiée. L'ensemble est pris à 100%, il correspond à l'aire totale du cercle, les aires des secteurs correspondent à des parties de l'ensemble. Construisons un diagramme sectoriel de la structure du commerce extérieur de la Fédération de Russie en 2006 selon le tableau. 2 (voir fig. 2). Lors de l'utilisation de programmes informatiques, les diagrammes de secteur sont construits sous forme tridimensionnelle, c'est-à-dire non pas sur deux, mais sur trois plans (voir Fig. 3).
Riz. 2. Graphique circulaire simple 3. Graphique circulaire 3D
Les diagrammes bouclés (image) améliorent la clarté de l'image, car ils incluent une image de l'indicateur affiché, dont la taille correspond à la taille de l'indicateur.
Lors du tracé d'un graphique, tout est également important - le bon choix d'une image graphique, les proportions, le respect des règles de conception des graphiques. Ces questions sont traitées plus en détail dans et.
Cartogrammes et cartogrammes sont utilisés pour représenter les caractéristiques géographiques des phénomènes étudiés. Ils montrent la localisation du phénomène étudié, son intensité sur un certain territoire - dans une république, une région, un district économique ou administratif, etc. La construction de cartogrammes et de cartogrammes est envisagée dans la littérature spécialisée, par exemple.
Fin du travail -
Ce sujet appartient à :
Le concept de statistiques
Le concept de statistique.. sujet et méthode de statistique.. résumé d'observation statistique et regroupement de données statistiques..
Si vous avez besoin de matériel supplémentaire sur ce sujet, ou si vous n'avez pas trouvé ce que vous cherchiez, nous vous recommandons d'utiliser la recherche dans notre base de données d'œuvres :
Que ferons-nous du matériel reçu :
Si ce matériel s'est avéré utile pour vous, vous pouvez l'enregistrer sur votre page sur les réseaux sociaux :
| tweeter |
Tous les sujets de cette section :
Le sujet et la méthode des statistiques
Le terme "statistiques" a été introduit dans l'usage scientifique par le scientifique allemand Gottfried Achenwal en 1746, qui a proposé de remplacer le titre du cours "Statistiques" enseigné dans les universités allemandes par "St
Observation statistique
Les gens ont des attitudes différentes à l'égard de l'information statistique : certains ne la perçoivent pas, d'autres y croient inconditionnellement, et d'autres encore sont d'accord avec l'opinion de l'homme politique anglais Disraeli : « Il y a 3 types de mensonges : mensonges,
Synthèse et regroupement des statistiques
Résumé - traitement scientifiquement organisé des matériaux d'observation (selon un programme préalablement développé), qui comprend, outre le contrôle obligatoire des données collectées, la systématisation, le regroupement
Valeurs absolues
Pour caractériser les phénomènes de masse, la statistique utilise des grandeurs statistiques (indicateurs) qui caractérisent des groupes d'unités ou un agrégat (phénomène) dans son ensemble. Grandeurs statistiques
Valeurs relatives
Une valeur relative est le résultat de la division (comparaison) de deux valeurs absolues. Le numérateur de la fraction est la valeur comparée et le dénominateur est la valeur comparée à (ba
Valeurs moyennes
Comme cela a été dit à maintes reprises, la statistique étudie les phénomènes et les processus de masse. Chacun de ces phénomènes a à la fois des propriétés communes à l'ensemble et des propriétés particulières, individuelles.
Construire une série de distribution
Les caractéristiques étudiées par les statistiques varient (diffèrent les unes des autres) pour différentes unités de la population au cours de la même période ou à un moment précis. Par exemple, la valeur du chiffre d'affaires du commerce extérieur varie
Calcul des caractéristiques structurelles de la série de distribution
Lors de l'étude de la variation, on utilise de telles caractéristiques d'une série de distribution qui décrivent quantitativement sa structure, sa structure. Telle est, par exemple, la médiane - la valeur de l'attribut variable
Calcul des mesures de taille et d'intensité de variation
L'indicateur le plus simple est la plage de variation - la différence absolue entre les valeurs maximales et minimales d'un trait par rapport aux valeurs disponibles dans la population étudiée (24):
Calcul des moments de distribution et indicateurs de sa forme
Pour une étude plus approfondie de la nature de la variation, les valeurs moyennes des différents degrés d'écart des valeurs individuelles d'un trait par rapport à sa valeur moyenne arithmétique sont utilisées. Ces indicateurs sont appelés
Vérifier si la série de distribution est normale
La courbe de distribution théorique s'entend comme une représentation graphique d'une série sous la forme d'une ligne continue de changement de fréquence dans une série variationnelle, fonctionnellement associée à un changement d'options, autre
Vérifier si la série de distribution est conforme à la loi de Poisson
L'inspection des douanes effectuait un contrôle après la mainlevée des marchandises. En conséquence, la série de distribution discrète suivante du nombre de violations identifiées dans chaque test a été obtenue (tableau 16). Tableau 1
Indicateurs absolus et relatifs de changement de structure
Le développement d'une population statistique se manifeste non seulement par la croissance ou la diminution quantitative des éléments du système, mais aussi par une modification de sa structure. La structure est la structure de l'agrégat
Indicateurs de classement du changement de structure
Pour mesurer les différences dans la structure, moins précises, mais plus faciles à calculer, on utilise souvent des indicateurs basés sur l'évaluation des différences non pas dans les valeurs des actions elles-mêmes, mais dans leurs rangs, c'est-à-dire ordinaux
Le concept d'observation sélective
La méthode d'échantillonnage est utilisée lorsque l'utilisation de l'observation continue est physiquement impossible en raison d'une énorme quantité de données ou n'est pas économiquement réalisable. Il y a une impossibilité physique
Méthodes d'échantillonnage
1. Sélection réellement aléatoire : toutes les unités du SH sont numérotées, et les numéros tirés à la suite du tirage correspondent aux unités qui sont tombées dans l'échantillon, et le nombre de numéros est égal au nombre prévu
Erreur d'échantillonnage moyenne
Après avoir terminé la sélection du nombre requis d'unités dans l'échantillon et enregistré les caractéristiques de ces unités prévues par le programme d'observation, ils procèdent au calcul des indicateurs de généralisation. à eux de
Erreur d'échantillonnage marginale
Considérant que sur la base d'une enquête par sondage, il est impossible d'évaluer avec précision le caractère généralisant du SH, il est nécessaire de trouver les limites dans lesquelles il se situe. Dans un échantillon particulier, la différence
Taille d'échantillon requise
Lors de l'élaboration d'un programme d'observation sélective, on leur attribue une valeur spécifique de l'erreur marginale et du niveau de probabilité. La taille minimale de l'échantillon qui fournit un
Des lignes directrices
Une tâche. Dans l'entreprise, 100 travailleurs sur 1000 ont été interrogés dans l'ordre d'un échantillon aléatoire non répétitif et les données suivantes ont été obtenues sur leur revenu du mois (tableau 24) : Ta
Le concept de séries temporelles
L'une des tâches les plus importantes des statistiques est l'étude des changements dans le temps des indicateurs analysés, c'est-à-dire leur dynamique. Ce problème est résolu en analysant la série de dynamiques (séries temporelles).
Indicateurs de changements dans les niveaux d'une série de dynamiques
L'analyse des séries chronologiques commence par déterminer comment les niveaux de la série changent (augmentent, diminuent ou restent inchangés) en termes absolus et relatifs. Tracer
Indicateurs moyens d'une série de dynamiques
Chaque série de dynamiques peut être considérée comme un certain ensemble de n indicateurs évoluant dans le temps, qui peuvent être résumés en valeurs moyennes. Ces indicateurs généralisés (moyens) sont particulièrement
Méthodes d'identification de la tendance principale (tendance) dans la série de dynamiques
L'une des principales tâches de l'étude de la série de dynamiques est d'identifier la tendance principale (modèle) dans l'évolution des niveaux de la série, appelée tendance. Régularité dans le changement des niveaux d'une série dans certains cas
Évaluation et prévision de l'adéquation des tendances
Pour l'équation de tendance trouvée, il est nécessaire d'évaluer sa fiabilité (adéquation), qui est généralement effectuée à l'aide du critère de Fisher, en comparant sa valeur calculée Fр
Analyse saisonnière
Dans la série de dynamiques, dont les niveaux sont des indicateurs mensuels ou trimestriels, ainsi que des fluctuations aléatoires, on observe souvent des fluctuations saisonnières, qui sont comprises comme périodiquement
Des lignes directrices
Selon le Service fédéral des statistiques de l'État, le solde du commerce extérieur (SVT) de la Russie pour la période 2000-2006. caractérisé par un certain nombre de dynamiques présentées dans le tableau. 36. Tableau 36. Balance commerciale extérieure (CBT) de la Russie pour p
Le concept de dépendance de corrélation
L'une des lois les plus générales du monde objectif est la loi de la connexion universelle et de la dépendance entre les phénomènes. Naturellement, lorsqu'il s'agit d'enquêter sur des phénomènes dans les domaines les plus divers, les statistiques se heurtent inévitablement
Méthodes d'identification et d'évaluation des corrélations
Un certain nombre de méthodes sont utilisées en statistique pour identifier la présence et la nature d'une corrélation entre deux caractéristiques. 1. Prise en compte des données parallèles (kn
Coefficients de corrélation de rang
Les coefficients de corrélation de rang sont des indicateurs non paramétriques moins précis, mais plus faciles à calculer, pour mesurer la proximité de la relation entre deux caractéristiques corrélées. Ceux-ci inclus
Particularités de la corrélation des séries chronologiques
Dans de nombreuses études, il est nécessaire d'étudier la dynamique de plusieurs indicateurs simultanément, c'est-à-dire considérer plusieurs séries temporelles en parallèle. Dans ce cas, il devient nécessaire de mesurer la dépendance
Indicateurs de l'étroitesse de la relation entre les caractéristiques qualitatives
La méthode des tableaux de corrélation s'applique non seulement aux caractéristiques quantitatives, mais également aux caractéristiques descriptives (qualitatives), dont la relation entre elles doit souvent être étudiée lors de la conduite de divers sociologues.
Corrélation multiple
Lors de la résolution de problèmes pratiques, les chercheurs sont confrontés au fait que les corrélations ne se limitent pas aux relations entre deux caractéristiques : y effectif et facteur x. En action
Objet et types d'indices
L'indice est une valeur relative montrant combien de fois le niveau du phénomène étudié dans des conditions données diffère du niveau du même phénomène dans d'autres conditions. La différence de conditions peut être
Indices individuels
La valeur relative obtenue en comparant les niveaux est appelée indice individuel si la structure du phénomène étudié importe peu. Les indices individuels sont désignés par i
Index généraux
Si le phénomène étudié est hétérogène et que la comparaison des niveaux ne peut se faire qu'après les avoir ramenés à une mesure commune, l'analyse économique s'effectue au moyen d'indices généraux. L'indice devient général
Indices moyens
Lors de l'étude d'indicateurs qualitatifs, il est souvent nécessaire de considérer l'évolution dans le temps (ou dans l'espace) de la valeur moyenne d'un indicateur indexé pour une certaine population homogène.
Indices territoriaux
Les indices territoriaux sont utilisés pour les comparaisons spatiales et interrégionales de divers indicateurs. Leur calcul est plus compliqué que le calcul des indices traditionnels (dynamiques) considérés