Der genetische Code wird kontinuierlich abgelesen. Genetischer Code: Beschreibung, Merkmale, Forschungsgeschichte
Lesen Sie auch
Genetische Funktionen der DNA sind, dass es die Speicherung, Übertragung und Implementierung ermöglicht erbliche Informationen, das Informationen über die Primärstruktur von Proteinen (d. h. ihre Aminosäurezusammensetzung) darstellt. Der Zusammenhang zwischen DNA und Proteinsynthese wurde bereits 1944 von den Biochemikern J. Beadle und E. Tatum vorhergesagt, als sie den Mechanismus von Mutationen im Schimmelpilz Neurospora untersuchten. Informationen werden mithilfe eines genetischen Codes als spezifische Sequenz stickstoffhaltiger Basen in einem DNA-Molekül aufgezeichnet. Die Entschlüsselung des genetischen Codes gilt als eine der großen naturwissenschaftlichen Entdeckungen des 20. Jahrhunderts. und wird in ihrer Bedeutung mit der Entdeckung der Kernenergie in der Physik gleichgesetzt. Der Erfolg auf diesem Gebiet ist mit dem Namen des amerikanischen Wissenschaftlers M. Nirenberg verbunden, in dessen Labor das erste Codon YYY entschlüsselt wurde. Allerdings dauerte der gesamte Entschlüsselungsprozess mehr als 10 Jahre, sagen viele berühmte Wissenschaftler verschiedene Länder, und zwar nicht nur Biologen, sondern auch Physiker, Mathematiker und Kybernetiker. Einen entscheidenden Beitrag zur Entwicklung des Mechanismus zur Aufzeichnung genetischer Informationen leistete G. Gamow, der als erster vorschlug, dass ein Codon aus drei Nukleotiden besteht. Durch die gemeinsame Anstrengung von Wissenschaftlern wurde es gegeben volle Eigenschaften genetischer Code.
Buchstaben im inneren Kreis sind Basen an der 1. Position im Codon, Buchstaben im zweiten Kreis sind es
Die Basen befinden sich an der 2. Position und die Buchstaben außerhalb des zweiten Kreises sind die Basen an der 3. Position.
Im letzten Kreis stehen die abgekürzten Namen der Aminosäuren. NP - unpolar,
P – polare Aminosäurereste.
Die Haupteigenschaften des genetischen Codes sind: Dreifachheit, Entartung Und nicht überlappend. Triplet bedeutet, dass eine Abfolge von drei Basen den Einbau einer bestimmten Aminosäure in ein Proteinmolekül bestimmt (zum Beispiel AUG – Methionin). Die Degeneration des Codes besteht darin, dass dieselbe Aminosäure von zwei oder mehr Codons codiert werden kann. Nicht überlappend bedeutet, dass dieselbe Base nicht in zwei benachbarten Codons vorkommen kann.
Es wurde festgestellt, dass der Code vorhanden ist Universal-, d.h. Das Prinzip der Erfassung genetischer Informationen ist bei allen Organismen gleich.
Tripletts, die dieselbe Aminosäure kodieren, werden synonyme Codons genannt. Sie haben meist die gleichen Basen an der 1. und 2. Position und unterscheiden sich nur in der dritten Base. Beispielsweise wird der Einbau der Aminosäure Alanin in ein Proteinmolekül durch synonyme Codons im RNA-Molekül kodiert – GCA, GCC, GCG, GCY. Der genetische Code enthält drei nichtkodierende Tripletts (Nonsense-Codons – UAG, UGA, UAA), die beim Lesen von Informationen die Rolle von Stoppsignalen spielen.
Es wurde festgestellt, dass die Universalität des genetischen Codes nicht absolut ist. Unter Beibehaltung des allen Organismen gemeinsamen Codierungsprinzips und der Merkmale des Codes wird in einer Reihe von Fällen eine Veränderung der semantischen Belastung einzelner Codewörter beobachtet. Dieses Phänomen wurde als Mehrdeutigkeit des genetischen Codes bezeichnet, und der Code selbst wurde als „Mehrdeutigkeit“ bezeichnet quasi-universal.
Lesen Sie auch andere Artikel Thema 6 „Molekulare Grundlagen der Vererbung“:
Lesen Sie weitere Themen im Buch weiter „Genetik und Selektion. Theorie. Aufgaben. Antworten“.
Nachdem Sie diese Themen durchgearbeitet haben, sollten Sie in der Lage sein:
- Beschreiben Sie die folgenden Konzepte und erläutern Sie die Beziehungen zwischen ihnen:
- Polymer, Monomer;
- Kohlenhydrate, Monosaccharide, Disaccharide, Polysaccharide;
- Lipid, Fettsäure, Glycerin;
- Aminosäure, Peptidbindung, Protein;
- Katalysator, Enzym, aktives Zentrum;
- Nukleinsäure, Nukleotid.
- Nennen Sie 5-6 Gründe, die Wasser zu einem so wichtigen Bestandteil lebender Systeme machen.
- Nennen Sie die vier Hauptklassen organische Verbindungen in lebenden Organismen enthalten; Beschreiben Sie die Rolle jedes einzelnen von ihnen.
- Erklären Sie, warum enzymkontrollierte Reaktionen von der Temperatur, dem pH-Wert und der Anwesenheit von Coenzymen abhängen.
- Erklären Sie die Rolle von ATP im Energiehaushalt der Zelle.
- Nennen Sie die Ausgangsstoffe, Hauptschritte und Endprodukte lichtinduzierter Reaktionen und Kohlenstofffixierungsreaktionen.
- Geben Kurzbeschreibung allgemeines Schema Zellatmung, aus der hervorgeht, wo die Glykolysereaktionen, der G.-Krebs-Zyklus (Zyklus), stattfinden Zitronensäure) und Elektronentransportkette.
- Vergleichen Sie Atmung und Fermentation.
- Beschreiben Sie die Struktur des DNA-Moleküls und erklären Sie, warum die Anzahl der Adeninreste gleich der Anzahl der Thyminreste und die Anzahl der Guaninreste gleich der Anzahl der Cytosinreste ist.
- Erstellen Sie ein kurzes Diagramm der RNA-Synthese aus DNA (Transkription) in Prokaryoten.
- Beschreiben Sie die Eigenschaften des genetischen Codes und erklären Sie, warum es sich um einen Triplett-Code handeln sollte.
- Bestimmen Sie anhand der angegebenen DNA-Kette und Codon-Tabelle die komplementäre Sequenz der Messenger-RNA, geben Sie die Codons der Transfer-RNA und die Aminosäuresequenz an, die als Ergebnis der Translation gebildet wird.
- Listen Sie die Etappen auf Proteinsynthese auf Ribosomenebene.
Algorithmus zur Lösung von Problemen.
Typ 1. Selbstkopie der DNA.
Eine der DNA-Ketten hat die folgende Nukleotidsequenz:
AGTACCGATACCGATTTACCG...
Welche Nukleotidsequenz hat die zweite Kette desselben Moleküls?
Um die Nukleotidsequenz des zweiten Strangs eines DNA-Moleküls zu schreiben, reicht es aus, wenn die Sequenz des ersten Strangs bekannt ist, Thymin durch Adenin, Adenin durch Thymin, Guanin durch Cytosin und Cytosin durch Guanin zu ersetzen. Nachdem wir diese Ersetzung vorgenommen haben, erhalten wir die Reihenfolge:
TATTGGGCTATGAGCTAAAATG...
Typ 2. Proteinkodierung.
Die Aminosäurekette des Ribonuklease-Proteins hat den folgenden Anfang: Lysin-Glutamin-Threonin-Alanin-Alanin-Alanin-Lysin...
Mit welcher Nukleotidsequenz beginnt das diesem Protein entsprechende Gen?
Verwenden Sie dazu die genetische Codetabelle. Für jede Aminosäure finden wir ihre Codebezeichnung in Form des entsprechenden Nukleotidtripels und schreiben sie auf. Indem wir diese Tripletts nacheinander in der gleichen Reihenfolge wie die entsprechenden Aminosäuren anordnen, erhalten wir die Formel für die Struktur eines Abschnitts der Boten-RNA. In der Regel gibt es mehrere solcher Drillinge, die Auswahl erfolgt nach Ihrer Entscheidung (es wird jedoch nur einer der Drillinge vergeben). Dementsprechend kann es mehrere Lösungen geben.
ААААААААЦУГЦГГЦУГЦГАAG
Mit welcher Aminosäuresequenz beginnt ein Protein, wenn es durch die folgende Nukleotidsequenz kodiert wird:
ACCTTCCATGGCCGGT...
Mithilfe des Komplementaritätsprinzips ermitteln wir die Struktur eines Abschnitts der Boten-RNA, der auf einem bestimmten Abschnitt eines DNA-Moleküls gebildet wird:
UGCGGGGUACCGGCCCA...
Dann wenden wir uns der Tabelle des genetischen Codes zu und suchen und schreiben für jedes Nukleotidtripel, beginnend mit dem ersten, die entsprechende Aminosäure aus:
Cystein-Glycin-Tyrosin-Arginin-Prolin-...
Ivanova T.V., Kalinova G.S., Myagkova A.N. " Allgemeine Biologie". Moskau, „Aufklärung“, 2000
- Thema 4. " Chemische Zusammensetzung Zellen.“ §2-§7 S. 7-21
- Thema 5. „Photosynthese“. §16-17 S. 44-48
- Thema 6. „Zellatmung“. §12-13 S. 34-38
- Thema 7. „Genetische Informationen“. §14-15 S. 39-44
GENETISCHER CODE, ein System zur Aufzeichnung erblicher Informationen in Form einer Sequenz von Nukleotidbasen in DNA-Molekülen (bei einigen Viren - RNA), das die Primärstruktur (Lage der Aminosäurereste) in Proteinmolekülen (Polypeptidmolekülen) bestimmt. Das Problem des genetischen Codes wurde nach dem Nachweis der genetischen Rolle der DNA (amerikanische Mikrobiologen O. Avery, K. McLeod, M. McCarthy, 1944) und der Entschlüsselung ihrer Struktur (J. Watson, F. Crick, 1953) formuliert dass Gene die Struktur und Funktionen von Enzymen bestimmen (das Prinzip „ein Gen – ein Enzym“ von J. Beadle und E. Tatem, 1941) und dass eine Abhängigkeit der räumlichen Struktur und Aktivität eines Proteins von seiner Primärstruktur besteht (F. Sanger, 1955). Die Frage, wie Kombinationen von 4 Nukleinsäurebasen den Wechsel von 20 gemeinsamen Aminosäureresten in Polypeptiden bestimmen, wurde erstmals 1954 von G. Gamow gestellt.
Basierend auf einem Experiment, in dem sie die Wechselwirkungen von Insertionen und Deletionen eines Nukleotidpaars in einem der Gene des T4-Bakteriophagen untersuchten, bestimmten F. Crick und andere Wissenschaftler 1961 die allgemeinen Eigenschaften des genetischen Codes: Triplettität, d. h. Jeder Aminosäurerest in der Polypeptidkette entspricht einem Satz von drei Basen (Triplett oder Codon) in der DNA eines Gens. Codons innerhalb eines Gens werden von einem festen Punkt aus in einer Richtung und „ohne Kommas“ gelesen, d. h. die Codons sind nicht durch irgendwelche Zeichen voneinander getrennt; Degeneration oder Redundanz – derselbe Aminosäurerest kann von mehreren Codons (synonymen Codons) kodiert werden. Die Autoren gingen davon aus, dass sich die Codons nicht überlappen (jede Base gehört nur zu einem Codon). Die direkte Untersuchung der Kodierungskapazität von Tripletts wurde mit einem zellfreien Proteinsynthesesystem unter der Kontrolle synthetischer Boten-RNA (mRNA) fortgesetzt. Bis 1965 wurde der genetische Code in den Werken von S. Ochoa, M. Nirenberg und H. G. Korana vollständig entschlüsselt. Die Entschlüsselung der Geheimnisse des genetischen Codes gehörte zu den herausragenden Errungenschaften der Biologie des 20. Jahrhunderts.
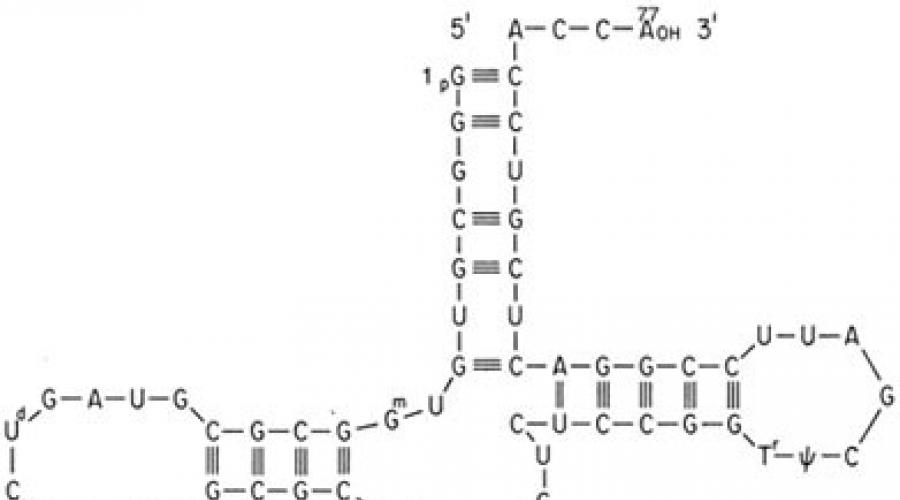
Die Implementierung des genetischen Codes in einer Zelle erfolgt während zweier Matrixprozesse – Transkription und Translation. Der Vermittler zwischen dem Gen und dem Protein ist mRNA, die bei der Transkription auf einem der DNA-Stränge entsteht. Dabei wird die DNA-Basensequenz, die Informationen über die Primärstruktur des Proteins trägt, in Form einer mRNA-Basensequenz „umgeschrieben“. Bei der Translation auf Ribosomen wird dann die Nukleotidsequenz der mRNA von Transfer-RNAs (tRNAs) abgelesen. Letztere haben ein Akzeptorende, an das ein Aminosäurerest gebunden ist, und ein Adapterende, oder Anticodon-Triplett, das das entsprechende mRNA-Codon erkennt. Die Wechselwirkung eines Codons und eines Anti-Codons erfolgt auf der Grundlage komplementärer Basenpaarung: Adenin (A) – Uracil (U), Guanin (G) – Cytosin (C); Dabei wird die Basensequenz der mRNA in die Aminosäuresequenz des synthetisierten Proteins übersetzt. Verschiedene Organismen Sie verwenden unterschiedliche synonyme Codons mit unterschiedlichen Frequenzen für dieselbe Aminosäure. Das Lesen der mRNA, die die Polypeptidkette kodiert, beginnt (initiiert) mit dem AUG-Codon, das der Aminosäure Methionin entspricht. Seltener sind die Initiationscodons bei Prokaryoten GUG (Valin), UUG (Leucin), AUU (Isoleucin) und bei Eukaryoten UUG (Leucin), AUA (Isoleucin), ACG (Threonin), CUG (Leucin). Dies legt den sogenannten Rahmen oder die Phase des Lesens während der Translation fest, d. h., dann wird die gesamte Nukleotidsequenz der mRNA Triplett für Triplett der tRNA gelesen, bis eines der drei Terminatorcodons, oft Stopcodons genannt, auftrifft die mRNA: UAA, UAG, UGA (Tabelle). Das Ablesen dieser Tripletts führt zum Abschluss der Synthese der Polypeptidkette.
AUG- und Stoppcodons erscheinen jeweils am Anfang und am Ende der mRNA-kodierenden Polypeptidregionen.
Der genetische Code ist quasi-universal. Dies bedeutet, dass es zwischen Objekten geringfügige Unterschiede in der Bedeutung einiger Codons gibt. Dies gilt in erster Linie für Terminatorcodons, die von Bedeutung sein können. Beispielsweise kodiert UGA in den Mitochondrien einiger Eukaryoten und Mykoplasmen für Tryptophan. Darüber hinaus kodiert UGA in einigen mRNAs von Bakterien und Eukaryoten für eine ungewöhnliche Aminosäure – Selenocystein, und UAG in einem der Archaebakterien – Pyrrolysin.
Es gibt eine Sichtweise, nach der der genetische Code durch Zufall entstanden ist (Hypothese des „eingefrorenen Zufalls“). Es ist wahrscheinlicher, dass es sich weiterentwickelt hat. Diese Annahme wird durch die Existenz einer einfacheren und offenbar älteren Version des Codes gestützt, der in Mitochondrien nach der „Zwei-von-Drei“-Regel gelesen wird, wenn die Aminosäure nur durch zwei der drei Basen bestimmt wird im Triplett.
Lit.: Crick F. N. a. Ö. Allgemeine Natur des genetischen Codes für Proteine // Natur. 1961. Bd. 192; Der genetische Code. N.Y., 1966; Ichas M. Biologischer Code. M., 1971; Inge-Vechtomov S.G. Wie der genetische Code gelesen wird: Regeln und Ausnahmen // Moderne Naturwissenschaft. M., 2000. T. 8; Ratner V. A. Genetischer Code als System // Soros-Bildungsjournal. 2000. T. 6. Nr. 3.
S. G. Inge-Vechtomov.
Der genetische Code ist ein System zur Aufzeichnung erblicher Informationen in Nukleinsäuremolekülen, das auf einer bestimmten Abwechslung von Nukleotidsequenzen in DNA oder RNA basiert und Codons bildet, die Aminosäuren in einem Protein entsprechen.
Eigenschaften des genetischen Codes.
Der genetische Code hat mehrere Eigenschaften.
Dreiheit.
Entartung oder Redundanz.
Eindeutigkeit.
Polarität.
Nicht überlappend.
Kompaktheit.
Vielseitigkeit.
Es ist zu beachten, dass einige Autoren auch andere Eigenschaften des Codes vorschlagen chemische Eigenschaften im Code der Nukleotide enthalten oder mit der Häufigkeit des Vorkommens einzelner Aminosäuren in den Proteinen des Körpers usw. Diese Eigenschaften ergeben sich jedoch aus den oben aufgeführten, sodass wir sie dort berücksichtigen.
A. Dreiheit. Der genetische Code verfügt, wie viele komplex organisierte Systeme, über die kleinste strukturelle und kleinste funktionelle Einheit. Ein Triplett ist die kleinste Struktureinheit des genetischen Codes. Es besteht aus drei Nukleotiden. Ein Codon ist die kleinste funktionelle Einheit des genetischen Codes. Typischerweise werden Tripletts der mRNA als Codons bezeichnet. Im genetischen Code erfüllt ein Codon mehrere Funktionen. Erstens besteht seine Hauptfunktion darin, dass es eine einzelne Aminosäure kodiert. Zweitens kodiert das Codon möglicherweise nicht für eine Aminosäure, erfüllt aber in diesem Fall eine andere Funktion (siehe unten). Wie aus der Definition hervorgeht, ist ein Triplett ein charakterisierender Begriff elementar Struktureinheit genetischer Code (drei Nukleotide). Codon – charakterisiert elementare semantische Einheit Genom – drei Nukleotide bestimmen die Bindung einer Aminosäure an die Polypeptidkette.
Die elementare Struktureinheit wurde zunächst theoretisch entschlüsselt und anschließend ihre Existenz experimentell bestätigt. Tatsächlich können 20 Aminosäuren nicht mit einem oder zwei Nukleotiden kodiert werden, weil Von letzteren gibt es nur 4. Drei von vier Nukleotiden ergeben 4 3 = 64 Varianten, was die Anzahl der in lebenden Organismen verfügbaren Aminosäuren mehr als abdeckt (siehe Tabelle 1).
Die in der Tabelle dargestellten 64 Nukleotidkombinationen weisen zwei Merkmale auf. Erstens sind von den 64 Triplett-Varianten nur 61 Codons und kodieren für jede beliebige Aminosäure, die sie nennen Sense-Codons. Drei Tripletts kodieren nicht
Aminosäuren a sind Stoppsignale, die das Ende der Translation anzeigen. Es gibt drei solcher Drillinge - UAA, UAG, UGA, sie werden auch „bedeutungslos“ (Nonsense-Codons) genannt. Durch eine Mutation, die mit dem Austausch eines Nukleotids in einem Triplett durch ein anderes verbunden ist, kann aus einem Sense-Codon ein Nonsense-Codon entstehen. Diese Art von Mutation wird aufgerufen Nonsens-Mutation. Wenn ein solches Stoppsignal innerhalb des Gens (in seinem Informationsteil) gebildet wird, wird der Prozess während der Proteinsynthese an dieser Stelle ständig unterbrochen – nur der erste (vor dem Stoppsignal) Teil des Proteins wird synthetisiert. Eine Person mit dieser Pathologie wird einen Proteinmangel verspüren und die mit diesem Mangel verbundenen Symptome verspüren. Beispielsweise wurde eine solche Mutation in dem Gen identifiziert, das für die Hämoglobin-Betakette kodiert. Es wird eine verkürzte inaktive Hämoglobinkette synthetisiert, die schnell zerstört wird. Dadurch entsteht ein Hämoglobinmolekül ohne Betakette. Es ist klar, dass ein solches Molekül seine Aufgaben wahrscheinlich nicht vollständig erfüllen wird. Es kommt zu einer schweren Krankheit, die sich als hämolytische Anämie entwickelt (Beta-Null-Thalassämie, vom griechischen Wort „Thalas“ – Mittelmeer, wo diese Krankheit erstmals entdeckt wurde).
Der Wirkungsmechanismus von Stop-Codons unterscheidet sich vom Wirkungsmechanismus von Sense-Codons. Dies folgt aus der Tatsache, dass für alle Codons, die Aminosäuren kodieren, entsprechende tRNAs gefunden wurden. Für Nonsense-Codons wurden keine tRNAs gefunden. Folglich ist tRNA nicht am Prozess des Stoppens der Proteinsynthese beteiligt.
CodonAUG (in Bakterien manchmal GUG) kodieren nicht nur die Aminosäuren Methionin und Valin, sondern sind es auchInitiator der Sendung .
B. Entartung oder Redundanz.
61 der 64 Tripletts kodieren 20 Aminosäuren. Dieser dreifache Überschuss der Anzahl der Tripletts gegenüber der Anzahl der Aminosäuren legt nahe, dass bei der Informationsübertragung zwei Kodierungsmöglichkeiten genutzt werden können. Erstens können nicht alle 64 Codons an der Kodierung von 20 Aminosäuren beteiligt sein, sondern nur 20 und zweitens können Aminosäuren von mehreren Codons kodiert werden. Untersuchungen haben gezeigt, dass die Natur die letztere Möglichkeit genutzt hat.
Seine Präferenz ist offensichtlich. Wenn von den 64 Varianten-Tripletts nur 20 an der Kodierung von Aminosäuren beteiligt wären, dann würden 44 Tripletts (von 64) nicht-kodierend bleiben, d. h. bedeutungslos (Unsinn-Codons). Zuvor haben wir darauf hingewiesen, wie gefährlich es für das Leben einer Zelle ist, ein kodierendes Triplett durch Mutation in ein Nonsense-Codon umzuwandeln – dies stört die normale Funktion der RNA-Polymerase erheblich und führt letztendlich zur Entstehung von Krankheiten. Derzeit sind drei Codons in unserem Genom Nonsense-Codons. Stellen Sie sich nun vor, was passieren würde, wenn die Anzahl der Nonsense-Codons um etwa das Fünfzehnfache zunehmen würde. Es ist klar, dass in einer solchen Situation der Übergang von normalen Codons zu Nonsense-Codons unermesslich höher sein wird.
Ein Code, bei dem eine Aminosäure durch mehrere Tripletts kodiert wird, wird als degeneriert oder redundant bezeichnet. Fast jede Aminosäure hat mehrere Codons. Somit kann die Aminosäure Leucin durch sechs Tripletts kodiert werden – UUA, UUG, TSUU, TsUC, TsUA, TsUG. Valin wird durch vier Tripletts kodiert, Phenylalanin nur durch zwei Tryptophan und Methionin kodiert durch ein Codon. Die Eigenschaft, die mit der Aufzeichnung derselben Informationen mit unterschiedlichen Symbolen verbunden ist, wird aufgerufen Entartung.
Die Anzahl der für eine Aminosäure bestimmten Codons korreliert gut mit der Häufigkeit des Vorkommens der Aminosäure in Proteinen.
Und das ist höchstwahrscheinlich kein Zufall. Je häufiger eine Aminosäure in einem Protein vorkommt, je häufiger das Codon dieser Aminosäure im Genom vertreten ist, desto höher ist die Wahrscheinlichkeit einer Schädigung mutagene Faktoren. Daher ist klar, dass ein mutiertes Codon eine größere Chance hat, dieselbe Aminosäure zu kodieren, wenn es stark degeneriert ist. Aus dieser Perspektive ist die Degeneration des genetischen Codes ein Mechanismus, der das menschliche Genom vor Schäden schützt.
Es ist zu beachten, dass der Begriff Degeneration in der Molekulargenetik in einem anderen Sinne verwendet wird. Somit ist der Großteil der Informationen in einem Codon in den ersten beiden Nukleotiden enthalten; die Base an der dritten Position des Codons erweist sich als von geringer Bedeutung. Dieses Phänomen wird „Entartung der dritten Base“ genannt. Letzteres Merkmal minimiert die Auswirkungen von Mutationen. Es ist beispielsweise bekannt, dass die Hauptfunktion der roten Blutkörperchen darin besteht, Sauerstoff von der Lunge zu den Geweben zu transportieren Kohlendioxid vom Gewebe bis zur Lunge. Diese Funktion übernimmt das Atmungspigment Hämoglobin, das das gesamte Zytoplasma des Erythrozyten ausfüllt. Es besteht aus einem Proteinteil – Globin, der vom entsprechenden Gen kodiert wird. Das Hämoglobinmolekül enthält neben Protein auch Häm, das Eisen enthält. Mutationen in Globin-Genen führen zum Auftreten Verschiedene Optionen Hämoglobine. Am häufigsten sind Mutationen damit verbunden Ersetzen eines Nukleotids durch ein anderes und Auftreten eines neuen Codons im Gen, das möglicherweise eine neue Aminosäure in der Hämoglobin-Polypeptidkette kodiert. In einem Triplett kann durch Mutation jedes Nukleotid ersetzt werden – das erste, zweite oder dritte. Es sind mehrere hundert Mutationen bekannt, die die Integrität der Globin-Gene beeinträchtigen. Nahe 400 davon sind mit dem Austausch einzelner Nukleotide in einem Gen und dem entsprechenden Aminosäureaustausch in einem Polypeptid verbunden. Nur von diesen 100 Ersatz führt zu einer Instabilität des Hämoglobins und verschiedenen Arten von Krankheiten von leicht bis sehr schwer. 300 (ca. 64 %) Substitutionsmutationen beeinträchtigen die Hämoglobinfunktion nicht und führen nicht zu einer Pathologie. Einer der Gründe dafür ist die oben erwähnte „Degeneration der dritten Base“, wenn ein Ersatz des dritten Nukleotids in einem Triplett, das Serin, Leucin, Prolin, Arginin und einige andere Aminosäuren kodiert, zum Auftreten eines synonymen Codons führt kodiert die gleiche Aminosäure. Eine solche Mutation wird sich phänotypisch nicht manifestieren. Im Gegensatz dazu führt jeder Austausch des ersten oder zweiten Nukleotids in einem Triplett in 100 % der Fälle zum Auftreten einer neuen Hämoglobinvariante. Aber auch in diesem Fall dürfen keine schwerwiegenden phänotypischen Störungen vorliegen. Der Grund dafür ist der Ersatz einer Aminosäure im Hämoglobin durch eine andere, der ersten ähnlich. physikalische und chemische Eigenschaften. Wenn beispielsweise eine Aminosäure mit hydrophilen Eigenschaften durch eine andere Aminosäure mit denselben Eigenschaften ersetzt wird.
Hämoglobin besteht aus der Eisenporphyringruppe Häm (Sauerstoff- und Kohlendioxidmoleküle sind daran gebunden) und Proteinglobin. Das erwachsene Hämoglobin (HbA) enthält zwei identische -Ketten und zwei -Ketten. Molekül -Kette enthält 141 Aminosäurereste, -Kette - 146, - Und -Ketten unterscheiden sich in vielen Aminosäureresten. Die Aminosäuresequenz jeder Globinkette wird von einem eigenen Gen kodiert. Genkodierung -die Kette befindet sich im kurzen Arm von Chromosom 16, -Gen – im kurzen Arm von Chromosom 11. Substitution in der Genkodierung -Die Hämoglobinkette des ersten oder zweiten Nukleotids führt fast immer zum Auftreten neuer Aminosäuren im Protein, zu einer Störung der Hämoglobinfunktionen und zu schwerwiegenden Folgen für den Patienten. Wenn beispielsweise „C“ in einem der Tripletts CAU (Histidin) durch „Y“ ersetzt wird, entsteht ein neues Triplett UAU, das eine andere Aminosäure kodiert – Tyrosin. Phänotypisch äußert sich dies in einer schweren Erkrankung. A Ähnlicher Ersatz auf Position 63 -Kette des Histidin-Polypeptids zu Tyrosin führt zu einer Destabilisierung des Hämoglobins. Es entwickelt sich die Krankheit Methämoglobinämie. Mutationsbedingter Ersatz von Glutaminsäure durch Valin an der 6. Stelle -Kette ist die Ursache der schwersten Krankheit – der Sichelzellenanämie. Lassen Sie uns die traurige Liste nicht fortsetzen. Beachten wir nur, dass beim Ersetzen der ersten beiden Nukleotide eine Aminosäure mit ähnlichen physikalisch-chemischen Eigenschaften wie die vorherige entstehen kann. Somit erfolgt der Ersatz des 2. Nukleotids in einem der Tripletts, die für Glutaminsäure (GAA) kodieren -Kette mit „U“ führt zum Auftreten eines neuen Tripletts (GUA), das Valin kodiert, und das Ersetzen des ersten Nukleotids durch „A“ bildet das Triplett AAA, das die Aminosäure Lysin kodiert. Glutaminsäure und Lysin haben ähnliche physikalisch-chemische Eigenschaften – sie sind beide hydrophil. Valin ist eine hydrophobe Aminosäure. Daher verändert der Ersatz von hydrophiler Glutaminsäure durch hydrophobes Valin die Eigenschaften von Hämoglobin erheblich, was letztendlich zur Entwicklung einer Sichelzellenanämie führt, während der Ersatz von hydrophiler Glutaminsäure durch hydrophiles Lysin die Funktion von Hämoglobin in geringerem Maße verändert – Patienten entwickeln eine milde Form von Anämie. Durch den Austausch der dritten Base kann das neue Triplett die gleichen Aminosäuren wie das vorherige kodieren. Wenn beispielsweise im CAC-Triplett Uracil durch Cytosin ersetzt wurde und ein CAC-Triplett erschien, werden beim Menschen praktisch keine phänotypischen Veränderungen festgestellt. Das ist verständlich, denn Beide Tripletts kodieren für die gleiche Aminosäure – Histidin.
Abschließend ist es angebracht zu betonen, dass die Degeneration des genetischen Codes und die Degeneration der dritten Base aus allgemeinbiologischer Sicht Schutzmechanismen sind, die der Evolution in der einzigartigen Struktur von DNA und RNA innewohnen.
V. Eindeutigkeit.
Jedes Triplett (außer Nonsens) kodiert nur eine Aminosäure. In der Richtung Codon – Aminosäure ist der genetische Code also eindeutig, in der Richtung Aminosäure – Codon ist er mehrdeutig (degeneriert).
Eindeutig
Aminosäure-Codon
Degenerieren
Und in diesem Fall ist die Notwendigkeit der Eindeutigkeit des genetischen Codes offensichtlich. Bei einer anderen Möglichkeit würden bei der Translation desselben Codons unterschiedliche Aminosäuren in die Proteinkette eingefügt und dadurch Proteine mit unterschiedlichen Primärstrukturen und unterschiedlichen Funktionen entstehen. Der Zellstoffwechsel würde auf die Funktionsweise „Ein Gen – mehrere Polypeptide“ umstellen. Es ist klar, dass in einer solchen Situation die regulatorische Funktion der Gene völlig verloren gehen würde.
G. Polarität
Das Auslesen von Informationen aus DNA und mRNA erfolgt nur in eine Richtung. Polarität ist wichtig für die Definition von Strukturen höherer Ordnung (sekundär, tertiär usw.). Zuvor haben wir darüber gesprochen, wie Strukturen niedrigerer Ordnung Strukturen höherer Ordnung bestimmen. Tertiärstruktur und Strukturen höherer Ordnung in Proteinen entstehen, sobald die synthetisierte RNA-Kette das DNA-Molekül verlässt oder die Polypeptidkette das Ribosom verlässt. Während das freie Ende einer RNA oder eines Polypeptids eine Tertiärstruktur annimmt, wird das andere Ende der Kette weiterhin an DNA (wenn RNA transkribiert wird) oder einem Ribosom (wenn ein Polypeptid transkribiert wird) synthetisiert.
Daher ist der unidirektionale Prozess des Lesens von Informationen (während der Synthese von RNA und Protein) nicht nur für die Bestimmung der Sequenz von Nukleotiden oder Aminosäuren in der synthetisierten Substanz, sondern auch für die strikte Bestimmung von Sekundär-, Tertiär- usw. wesentlich. Strukturen.
d. Nicht überlappend.
Der Code kann überlappend oder nicht überlappend sein. Die meisten Organismen haben einen nicht überlappenden Code. In einigen Phagen wird überlappender Code gefunden.
Das Wesen eines nicht überlappenden Codes besteht darin, dass ein Nukleotid eines Codons nicht gleichzeitig ein Nukleotid eines anderen Codons sein kann. Wenn der Code überlappend wäre, könnte die Sequenz aus sieben Nukleotiden (GCUGCUG) nicht wie im Fall eines nicht überlappenden Codes zwei Aminosäuren (Alanin-Alanin) (Abb. 33, A) codieren, sondern drei (falls vorhanden). ein Nukleotid gemeinsam) (Abb. 33, B) oder fünf (wenn zwei Nukleotide gemeinsam sind) (siehe Abb. 33, C). In den letzten beiden Fällen würde eine Mutation eines beliebigen Nukleotids zu einer Verletzung der Reihenfolge von zwei, drei usw. führen. Aminosäuren.
Es wurde jedoch festgestellt, dass eine Mutation eines Nukleotids immer den Einbau einer Aminosäure in ein Polypeptid stört. Dies ist ein wichtiges Argument dafür, dass sich der Code nicht überschneidet.
Lassen Sie uns dies in Abbildung 34 erklären. Fette Linien zeigen Tripletts, die Aminosäuren kodieren, im Fall von nicht überlappendem und überlappendem Code. Experimente haben eindeutig gezeigt, dass sich der genetische Code nicht überschneidet. Ohne auf Details des Experiments einzugehen, stellen wir fest, dass, wenn Sie das dritte Nukleotid in der Nukleotidsequenz ersetzen (siehe Abb. 34)U (mit einem Sternchen markiert) auf etwas anderes:
1. Bei einem nicht überlappenden Code würde das von dieser Sequenz kontrollierte Protein eine Substitution einer (ersten) Aminosäure (mit Sternchen markiert) aufweisen.
2. Bei einem überlappenden Code in Option A würde eine Substitution in zwei (ersten und zweiten) Aminosäuren (mit Sternchen markiert) erfolgen. Bei Option B würde der Austausch drei Aminosäuren betreffen (mit Sternchen markiert).
Zahlreiche Experimente haben jedoch gezeigt, dass bei der Störung eines Nukleotids in der DNA die Störung im Protein immer nur eine Aminosäure betrifft, was typisch für einen nicht überlappenden Code ist.
GZUGZUG GZUGZUG GZUGZUG
AGB AGB AGB UGC AGB AGB AGB UGC AGB AGB AGB
*** *** *** *** *** ***
Alanin - Alanin Ala - Cis - Ley Ala - Ley - Ley - Ala - Ley
A B C
Nicht überlappender Code. Überlappender Code
Reis. 34. Ein Diagramm, das das Vorhandensein eines nicht überlappenden Codes im Genom erklärt (Erklärung im Text).
Die Nichtüberlappung des genetischen Codes ist mit einer anderen Eigenschaft verbunden – das Lesen von Informationen beginnt an einem bestimmten Punkt – dem Initiationssignal. Ein solches Initiationssignal in mRNA ist das Codon, das für Methionin AUG kodiert.
Es ist zu beachten, dass der Mensch immer noch über eine geringe Anzahl von Genen verfügt, die davon abweichen allgemeine Regel und überlappen.
e. Kompaktheit.
Es gibt keine Interpunktion zwischen Codons. Mit anderen Worten: Tripletts sind beispielsweise nicht durch ein bedeutungsloses Nukleotid voneinander getrennt. Das Fehlen von „Satzzeichen“ im genetischen Code wurde in Experimenten nachgewiesen.
Und. Vielseitigkeit.
Der Code ist für alle auf der Erde lebenden Organismen derselbe. Ein direkter Beweis für die Universalität des genetischen Codes wurde durch den Vergleich von DNA-Sequenzen mit entsprechenden Proteinsequenzen erhalten. Es stellte sich heraus, dass alle bakteriellen und eukaryotischen Genome dieselben Codewerte verwenden. Es gibt Ausnahmen, aber nicht viele.
Die ersten Ausnahmen von der Universalität des genetischen Codes wurden in den Mitochondrien einiger Tierarten gefunden. Dabei handelte es sich um das Terminatorcodon UGA, das genauso lautet wie das Codon UGG, das für die Aminosäure Tryptophan kodiert. Es wurden auch andere seltenere Abweichungen von der Universalität festgestellt.
DNA-Codesystem.
Der genetische Code der DNA besteht aus 64 Nukleotidtripeln. Diese Tripletts werden Codons genannt. Jedes Codon kodiert für eine der 20 Aminosäuren, die bei der Proteinsynthese verwendet werden. Dies führt zu einer gewissen Redundanz im Code: Die meisten Aminosäuren werden durch mehr als ein Codon codiert.
Ein Codon erfüllt zwei miteinander verbundene Funktionen: Es signalisiert den Beginn der Translation und kodiert den Einschluss der Aminosäure Methionin (Met) in die wachsende Polypeptidkette. Das DNA-Kodierungssystem ist so konzipiert, dass der genetische Code entweder als RNA-Codons oder als DNA-Codons ausgedrückt werden kann. RNA-Codons finden sich in RNA (mRNA) und diese Codons sind in der Lage, Informationen während der Synthese von Polypeptiden zu lesen (ein Prozess, der als Translation bezeichnet wird). Aber jedes mRNA-Molekül erhält bei der Transkription vom entsprechenden Gen eine Nukleotidsequenz.
Alle bis auf zwei Aminosäuren (Met und Trp) können durch 2 bis 6 verschiedene Codons kodiert werden. Das Genom der meisten Organismen zeigt jedoch, dass bestimmte Codons gegenüber anderen bevorzugt sind. Beim Menschen wird Alanin beispielsweise viermal häufiger von GCC kodiert als von GCG. Dies weist wahrscheinlich auf eine höhere Translationseffizienz des Translationsapparats (z. B. des Ribosoms) für einige Codons hin.

Der genetische Code ist nahezu universell. Dieselben Codons sind demselben Aminosäureabschnitt zugeordnet und dieselben Start- und Stoppsignale sind bei Tieren, Pflanzen und Mikroorganismen überwiegend gleich. Es wurden jedoch einige Ausnahmen gefunden. Bei den meisten geht es darum, einer Aminosäure ein oder zwei der drei Stoppcodons zuzuordnen.
1. Der Code ist Triplett.
2. Der Code ist degeneriert.
3. Der Code ist eindeutig.
4. Der Code ist kollinear.
5. Der Code überschneidet sich nicht.
6. Der Code ist universell.
1) Der Code ist Triplett. 3 benachbarte Nukleotide tragen Informationen über ein Protein. Es kann 64 solcher Drillinge geben (dies zeigt die Redundanz des genetischen Codes), aber nur 61 von ihnen tragen Informationen über das Protein (Codons). Die 3 Tripletts werden Anticodons genannt und sind Stoppsignale, bei denen die Proteinsynthese stoppt.
2) Der Code ist degeneriert. Mehrere Codons können für eine Aminosäure kodieren.
3) Der Code ist klar. Jedes Codon kodiert nur für eine Aminosäure.
4) Der Code ist kollinear. Die Nukleotidsequenz in einem Gen entspricht der Aminosäuresequenz in einem Protein.
5) Der Code wird nicht überschrieben. Das gleiche Nukleotid kann nicht Teil von zwei unterschiedlichen Codons sein; die Ablesung erfolgt fortlaufend, hintereinander, bis zum Stoppcodon. Der Code enthält keine „Satzzeichen“.
6) Der Code ist universell. Dasselbe gilt für alle Lebewesen, d.h. das gleiche Triplett kodiert für die gleiche Aminosäure.
61. In welchen Fällen hat eine Änderung der Nukleotidsequenz in einem Gen keinen Einfluss auf die Struktur und Funktion des kodierenden Proteins?
1) wenn durch einen Nukleotidaustausch ein anderes Codon entsteht, das dieselbe Aminosäure kodiert;
2) wenn das durch einen Nukleotidaustausch gebildete Codon eine andere, aber ähnliche Aminosäure kodiert chemische Eigenschaften, was die Struktur des Proteins nicht verändert;
3) wenn Nukleotidveränderungen in intergenen oder nicht funktionierenden DNA-Regionen auftreten.
№62. DNA Replikation.
Reproduzieren- Prozess der Synthese eines Tochtermoleküls Desoxyribo Nukleinsäure auf der Matrize des übergeordneten DNA-Moleküls. Bei der anschließenden Teilung der Mutterzelle erhält jede Tochterzelle eine Kopie eines DNA-Moleküls, das mit der DNA der ursprünglichen Mutterzelle identisch ist. Dieser Prozess stellt sicher, dass genetische Informationen korrekt von Generation zu Generation weitergegeben werden. Die DNA-Replikation wird von einem komplexen Enzymkomplex durchgeführt, der aus 15–20 verschiedenen Proteinen besteht und Replisom genannt wird.
Zum Zeitpunkt der Teilung muss die DNA vollständig und nur einmal repliziert werden. Die Replikation erfolgt in drei Phasen:
1. Einleitung der Replikation (DNA-Polymerase beginnt mit der DNA-Replikation durch Bindung an ein Segment einer Nukleotidkette. An einer bestimmten Stelle (dem Ausgangspunkt der Replikation) kommt es zu einer lokalen Denaturierung der DNA, die Ketten divergieren und es werden zwei Replikationsgabeln gebildet. in entgegengesetzte Richtungen bewegen.).
2. Elongation (ein Schritt in der Biosynthese von Nukleinsäuremolekülen, der aus der sequentiellen Addition von Monomeren (Nukleotiden) an die wachsende DNA-Kette besteht).
3. Beendigung der Replikation (das letzte Stadium tritt in dem Moment ein, in dem leere Abschnitte zwischen Okazaki-Fragmenten mit Nukleotiden gefüllt werden).
Hauptteil:
Da es sich bei der DNA um ein vererbtes Molekül handelt, muss sie sich zur Verwirklichung dieser Eigenschaft selbst genau kopieren und somit alle im ursprünglichen DNA-Molekül verfügbaren Informationen in Form einer spezifischen Nukleotidsequenz bewahren. Dies wird durch einen speziellen Prozess erreicht, der der Teilung jeder Zelle im Körper vorausgeht und der als DNA-Replikation bezeichnet wird – der Prozess der Synthese eines Tochtermoleküls der Desoxyribonukleinsäure auf der Matrix des übergeordneten DNA-Moleküls.
Die DNA-Replikation erfolgt in drei Phasen:
1. Einleitung. Es liegt darin, dass spezielle Enzyme – DNA-Helikasen, die die doppelsträngige DNA-Helix abwickeln, die schwachen Wasserstoffbrücken aufbrechen, die die Nukleotide der beiden Ketten verbinden. Dadurch werden die DNA-Stränge getrennt und freie Stickstoffbasen „ragen“ aus jedem Strang heraus (das Erscheinungsbild einer sogenannten Replikationsgabel).
2. Verlängerung(das Stadium der Biosynthese von Nukleinsäuremolekülen, das aus der sequentiellen Addition von Monomeren (Nukleotiden) an die wachsende DNA-Kette besteht). Jeder der beiden DNA-Stränge dient als Vorlage für die Synthese eines neuen Strangs. Da die Elternstränge antiparallel sind, findet eine kontinuierliche DNA-Replikation nur auf einem Strang statt, der als Leitstrang bezeichnet wird. Ein spezielles Enzym, die DNA-Polymerase, beginnt sich entlang des freien DNA-Strangs vom 5-Zoll- zum 3-Zoll-Ende zu bewegen und hilft dabei, freie Nukleotide, die ständig in der Zelle synthetisiert werden, an das 3-Zoll-Ende des neu synthetisierten DNA-Strangs zu binden Die Synthese eines neuen Strangs auf dem nacheilenden Strang erfordert die ständige Bildung neuer Primer (sogenannte Primer – kurze Nukleinsäurefragmente, die von der DNA verwendet werden). - Polymerasen zur Initiierung der DNA-Synthese), um die Replikation zu starten, und erfolgt in kleinen Segmenten von jeweils 1000–2000 Nukleotiden (Okazaki-Fragmente). Die Samen werden abgebaut, nachdem die Synthese des nächsten Okazaki-Fragments abgeschlossen ist. Die resultierenden benachbarten DNA-Fragmente werden durch DNA-Ligase verbunden. Topoisomerase entfernt Superspiralen der Helix, Helikase sorgt für die Abwicklung Doppelhelix Das SSB-Protein sorgt für die Stabilität einzelsträngiger DNA.
3. Die Beendigung (Abschluss) der Replikation erfolgt, wenn die Lücken zwischen Okazaki-Fragmenten mit Nukleotiden (unter Beteiligung von DNA-Ligase) gefüllt werden, um zwei kontinuierliche DNA-Doppelstränge zu bilden, und wenn zwei Replikationsgabeln aufeinandertreffen. Anschließend wird die synthetisierte DNA zu Superhelixen verdreht.
63. Beschreiben Sie die Abfolge der Prozesse, die während der DNA-Replikation in Eukaryoten ablaufen
Die DNA-Replikationsmechanismen von Prokaryoten und Eukaryoten unterscheiden sich erheblich darin, dass im zweiten Fall die Synthese der führenden und nacheilenden DNA-Stränge durch unterschiedliche DNA-Polymerasen (Alpha bzw. Delta) erfolgt, während in E. coli beide DNA-Stränge vorhanden sind synthetisiert durch ein Dimer der DNA-Polymerase III. DNA-Polymerase Alpha initiiert die Synthese des Leitstrangs am Replikationsursprung, und DNA-Polymerase Delta führt eine zyklische Neuinitiierung der Synthese von Okazaki-Fragmenten durch, wobei sie offenbar das Vorhandensein des 5"-terminalen Nukleotids des nächsten Primers erkennt und anschließend davon dissoziiert die Matrizen-DNA und deren Anbindung zur erneuten Initiierung der Synthese des nächsten Okazaki-Fragments.
Die Reifung von Okazaki-Fragmenten in Eukaryoten erfordert die Entfernung von RNA-Primern mithilfe von 5"->3"-Exonuklease (Proteinfaktoren FEN-1 oder MF-1) und RNase H1 sowie die kovalente Verbindung von Fragmenten untereinander unter der Wirkung von DNA-Ligase ICH.
Es ist derzeit nicht bekannt, was genau als Auslösesignal für den Start der DNA-Replikation in der S-Phase dient. Das auslösende Ereignis, nach dem die DNA-Synthese beginnt, findet an bestimmten Stellen statt, die als „Replikationsgabeln“ bezeichnet werden. Während der S-Phase werden Cluster von Replikationsgabeln gleichzeitig auf allen Chromosomen aktiviert.
Die Position der Replikationsursprünge in Genen kann wichtig sein biologische Bedeutung. Die Tatsache, dass bei einer Reihe tierischer Viren die Replikation an bestimmten Stellen im Genom beginnt, legt nahe, dass Replikationsursprünge spezialisierte Sequenzen in der chromosomalen DNA sind. Der durchschnittliche Abstand zwischen Replikationsursprüngen ist vergleichbar mit dem durchschnittlichen Abstand zwischen benachbarten Chromatinschleifen. Daher ist es möglich, dass es in jeder Schleife nur einen Replikationsursprung gibt.
Wenn zwei Replikationszweige vom gleichen Replikationsursprung auf gegenüberliegenden Seiten dieses Punktes abweichen, landen die Eltern-Nukleosomen in unterschiedlichen Tochter-DNA-Helices. In diesem Fall bestimmt die genaue Position des Replikationsursprungs in der Transkriptionseinheit die Verteilung bereits vorhandener Elternhistone zwischen den beiden Tochtergenen. Nicht alle Nukleosomen sind exakt gleich – die Chromatinstruktur ist in verschiedenen Bereichen des genetischen Materials unterschiedlich. Die genaue Position des Replikationsursprungs in einem Gen könnte daher eine wichtige biologische Bedeutung haben, da sie die Chromatinstruktur dieses Gens in der nächsten Zellgeneration bestimmen würde.
Der Auslöser der DNA-Replikation funktioniert eindeutig nach dem Prinzip „Alles oder nichts“, da die DNA-Replikation, die in der S-Phase beginnt, fortgesetzt wird, bis der Prozess abgeschlossen ist. Der Replikationsprozess kann nach dem Prinzip „Alles oder Nichts“ von mindestens zwei Personen gesteuert werden verschiedene Wege:
1) einige allgemeines System kann jede chromosomale Bande spezifisch erkennen, sie dekondensieren und dadurch alle Replikationsursprünge gleichzeitig für Proteine zugänglich machen, die für die Bildung von Replikationsblasen verantwortlich sind;
2) Replikationsproteine können nur wenige Replikationsursprünge aus einem bestimmten Satz erkennen, woraufhin die begonnene lokale Replikation die Struktur des restlichen Chromatins der Replikationseinheit so verändert, dass eine Replikation an allen anderen Ursprüngen möglich wird.
Es ist möglich, dass ein kritischer Punkt in der Ereigniskette, die die DNA-Replikation initiiert, das Erreichen eines bestimmten Stadiums im Duplikationsprozess des Zentriols ist, das sowohl als Teil eines wichtigen Mikrotubuli-Organisationszentrums fungiert, das eng mit dem Interphase-Kern verbunden ist, als auch als ein Bestandteil jedes Spindelpols während der Mitose. Das Zentriol scheint sich durch einen Template-Prozess einmal pro Zellzyklus zu duplizieren (Abbildung 11-19).
Es ist auch noch nicht bekannt, was die feste Replikation der Chromosomenbänder bestimmt. Zur Erklärung dieser Sequenz wurden zwei Hypothesen vorgeschlagen. Einer von ihnen zufolge werden in der S-Phase verschiedene replikative Proteine synthetisiert, von denen jedes spezifisch für Chromosomenbänder eines bestimmten Typs ist andere Zeit. Einer anderen Hypothese zufolge, die mittlerweile plausibler erscheint, wirken replikative Proteine einfach auf diejenigen Teile der DNA ein, die für sie leichter zugänglich sind; Während der S-Phase kann es beispielsweise zu einer kontinuierlichen Dekondensation der Chromosomen kommen, und eine nach der anderen werden die Chromosomenbänder für Replikationsproteine zugänglich.