16 регрессионный анализ. Методы математической статистики
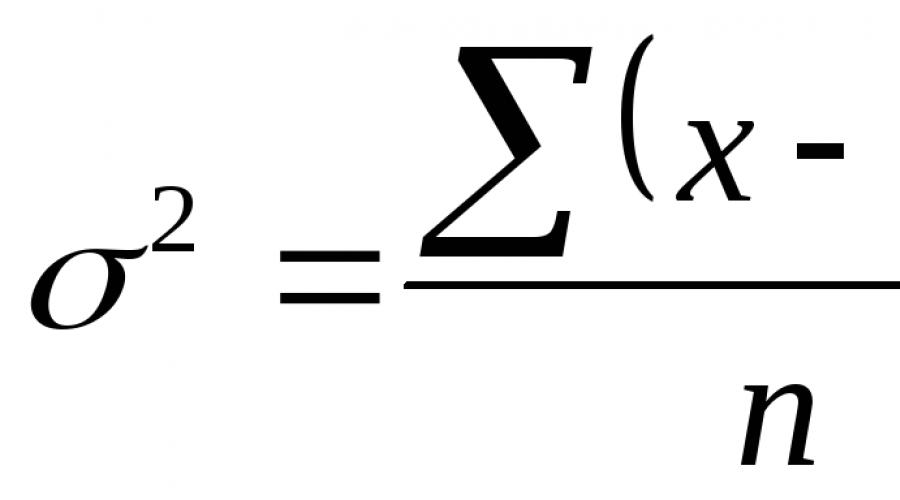
Читайте также
Регрессионный анализ исследует зависимость определенной величины от другой величины или нескольких других величин. Регрессионный анализ применяется преимущественно в среднесрочном прогнозировании, а также в долгосрочном прогнозировании. Средне- и долгосрочный периоды дают возможность установления изменений в среде бизнеса и учета влияний этих изменений на исследуемый показатель.
Для осуществления регрессионного анализа необходимо:
наличие ежегодных данных по исследуемым показателям,
наличие одноразовых прогнозов, т.е. таких прогнозов, которые не поправляются с поступлением новых данных.
Регрессионный анализ обычно проводится для объектов, имеющих сложную, многофакторную природу, таких как, объем инвестиций, прибыль, объемы продаж и др.
При нормативном методе прогнозирования определяются пути и сроки достижения возможных состояний явления, принимаемых в качестве цели. Речь идет о прогнозировании достижения желательных состояний явления на основе заранее заданных норм, идеалов, стимулов и целей. Такой прогноз отвечает на вопрос: какими путями можно достичь желаемого? Нормативный метод чаще применяется для программных или целевых прогнозов. Используются как количественное выражение норматива, так и определенная шкала возможностей оценочной функции
В случае использования количественного выражения, например физиологических и рациональных норм потребления отдельных продовольственных и непродовольственных товаров, разработанных специалистами для различных групп населения, можно определить уровень потребления этих товаров на годы, предшествующие достижению указанной нормы. Такие расчеты называют интерполяцией. Интерполяция - это способ вычисления показателей, недостающих в динамическом ряду явления, на основе установленной взаимосвязи. Принимая фактическое значение показателя и значение его нормативов за крайние члены динамического ряда, можно определить величины значений внутри этого ряда. Поэтому интерполяцию считают нормативным методом. Ранее приведенная формула (4), используемая в экстраполяции, может применяться в интерполяции, где у п будет характеризовать уже не фактические данные, а норматив показателя.
В случае использования в нормативном методе шкалы (поля, спектра) возможностей оценочной функции, т. е. функции распределения предпочтительности, указывают примерно следующую градацию: нежелательно - менее желательно - более желательно - наиболее желательно - оптимально (норматив).
Нормативный метод прогнозирования помогает выработать рекомендации по повышению уровня объективности, следовательно, эффективности решений.
Моделирование , пожалуй, самый сложный метод прогнозирования. Математическое моделирование означает описание экономического явления посредством математических формул, уравнений и неравенств. Математической аппарат должен достаточно точно отражать прогнозный фон, хотя полностью отразить всю глубину и сложность прогнозируемого объекта довольно трудно. Термин "модель" образован от латинского слова modelus, что означает "мера". Поэтому моделирование правильнее было бы считать не методом прогнозирования, а методом изучения аналогичного явления на модели.
В широком смысле моделями называются заместители объекта исследования, находящиеся с ним в таком сходстве, которое позволяет получить новое знание об объекте. Модель следует рассматривать как математическое описание объекта. В этом случае модель определяется как явление (предмет, установка), которое находиться в некотором соответствии с изучаемым объектом и может его замещать в процессе исследования, представляя информацию об объекте.
При более узком понимании модели она рассматривается как объект прогнозирования, ее исследование позволяет получить информацию о возможных состояниях объекта в будущем и путях достижения этих состояний. В этом случае целью прогнозной модели является получение информации не об объекте вообще, а только о его будущих состояниях. Тогда при построении модели бывает невозможно провести прямую проверку ее соответствия объекту, так как модель представляет собой только его будущее состояние, а сам объект в настоящее время может отсутствовать или иметь иное существование.
Модели могут быть материальными и идеальными.
В экономике используются идеальные модели. Наиболее совершенной идеальной моделью количественного описания социально-экономического (экономического) явления является математическая модель, использующая числа, формулы, уравнения, алгоритмы или графическое представление. С помощью экономических моделей определяют:
зависимость между различными экономическими показателями;
различного рода ограничения, накладываемые на показатели;
критерии, позволяющие оптимизировать процесс.
Содержательное описание объекта может быть представлено в виде его формализованной схемы, которая указывает, какие параметры и исходную информацию нужно собрать, чтобы вычислить искомые величины. Математическая модель в отличие от формализованной схемы содержит конкретные числовые данные, характеризующие объект Разработка математической модели во многом зависит от представления прогнозиста о сущности моделируемого процесса. На основе своих представлений он выдвигает рабочую гипотезу, с помощью которой создается аналитическая запись модели в виде формул, уравнений и неравенств. В результате решения системы уравнений получают конкретные параметры функции, которыми описывается изменение искомых переменных величин во времени.
Порядок и последовательность работы как элемент организации прогнозирования определяется в зависимости от применяемого метода прогнозирования. Обычно эта работа выполняется в несколько этапов.
1-й этап - прогнозная ретроспекция, т. е. установление объекта прогнозирования и прогнозного фона. Работа на первом этапе выполняется в такой последовательности:
формирование описания объекта в прошлом, что включает предпрогнозный анализ объекта, оценку его параметров, их значимости и взаимных связей,
определение и оценка источников информации, порядка и организации работы с ними, сбор и размещение ретроспективной информации;
постановка задач исследования.
Выполняя задачи прогнозной ретроспекции, прогнозисты исследуют историю развития объекта и прогнозного фона с целью получения их систематизированного описания.
2-й этап - прогнозный диагноз, в ходе которого исследуется систематизированное описание объекта прогнозирования и прогнозного фона с целью выявления тенденций их развития и выбора моделей и методов прогнозирования. Работа выполняется в такой последовательности:
разработка модели объекта прогноза, в том числе формализованное описание объекта, проверка степени адекватности модели объекту;
выбор методов прогнозирования (основного и вспомогательных), разработка алгоритма и рабочих программ.
3-й этап - протекция, т. е. процесс обширной разработки прогноза, в том числе: 1) расчет прогнозируемых параметров на заданный период упреждения; 2) синтез отдельных составляющих прогноза.
4-й этап - оценка прогноза, в том числе его верификация, т. е. определение степени достоверности, точности и обоснованности.
В ходе проспекции и оценки на основании предыдущих этапов решаются задачи прогноза и его оценка.
Указанная этапность является примерной и зависит от основного метода прогнозирования.
Результаты прогноза оформляются в виде справки, доклада или иного материала и представляются заказчику.
В прогнозировании может быть указана величина отклонения прогноза от действительного состояния объекта, которая называется ошибкой прогноза, которая рассчитывается по формуле:
;
 ;
; .
(9.3)
.
(9.3)
Источники ошибок в прогнозировании
Основными источниками могут быть:
1. Простое перенесение (экстраполяция) данных из прошлого в будущее (например, отсутствие у фирмы иных вариантов прогноза, кроме 10% роста продаж).
2. Невозможность точно определить вероятность события и его воздействия на исследуемый объект.
3. Непредвиденные трудности (разрушительные события), влияющие на осуществление плана, например, внезапное увольнение начальника отдела сбыта.
В целом точность прогнозирования повышается по мере накопления опыта прогнозирования и отработки его методов.
Регрессионный анализ -- метод моделирования измеряемых данных и исследования их свойств. Данные состоят из пар значений зависимой переменной (переменной отклика) и независимой переменной (объясняющей переменной). Регрессионная модель есть функция независимой переменной и параметров с добавленной случайной переменной.
Корреляционный анализ и регрессионный анализ являются смежными разделами математической статистики, и предназначаются для изучения по выборочным данным статистической зависимости ряда величин; некоторые из которых являются случайными. При статистической зависимости величины не связаны функционально, но как случайные величины заданы совместным распределением вероятностей.
Исследование зависимости случайных величин приводит к моделям регрессии и регрессионному анализу на базе выборочных данных. Теория вероятностей и математическая статистика представляют лишь инструмент для изучения статистической зависимости, но не ставят своей целью установление причинной связи. Представления и гипотезы о причинной связи должны быть привнесены из некоторой другой теории, которая позволяет содержательно объяснить изучаемое явление.
Числовые данные обычно имеют между собой явные (известные) или неявные (скрытые) связи.
Явно связаны показатели, которые получены методами прямого счета, т. е. вычислены по заранее известным формулам. Например, проценты выполнения плана, уровни, удельные веса, отклонения в сумме, отклонения в процентах, темпы роста, темпы прироста, индексы и т. д.
Связи же второго типа (неявные) заранее неизвестны. Однако необходимо уметь объяснять и предсказывать (прогнозировать) сложные явления для того, чтобы управлять ими. Поэтому специалисты с помощью наблюдений стремятся выявить скрытые зависимости и выразить их в виде формул, т. е. математически смоделировать явления или процессы. Одну из таких возможностей предоставляет корреляционно-регрессионный анализ.
Математические модели строятся и используются для трех обобщенных целей:
- * для объяснения;
- * для предсказания;
- * для управления.
Пользуясь методами корреляционно-регрессионного анализа, аналитики измеряют тесноту связей показателей с помощью коэффициента корреляции. При этом обнаруживаются связи, различные по силе (сильные, слабые, умеренные и др.) и различные по направлению (прямые, обратные). Если связи окажутся существенными, то целесообразно будет найти их математическое выражение в виде регрессионной модели и оценить статистическую значимость модели.
Регрессионный анализ называют основным методом современной математической статистики для выявления неявных и завуалированных связей между данными наблюдений.
Постановка задачи регрессионного анализа формулируется следующим образом.
Имеется совокупность результатов наблюдений. В этой совокупности один столбец соответствует показателю, для которого необходимо установить функциональную зависимость с параметрами объекта и среды, представленными остальными столбцами. Требуется: установить количественную взаимосвязь между показателем и факторами. В таком случае задача регрессионного анализа понимается как задача выявления такой функциональной зависимости y = f (x2, x3, …, xт), которая наилучшим образом описывает имеющиеся экспериментальные данные.
Допущения:
количество наблюдений достаточно для проявления статистических закономерностей относительно факторов и их взаимосвязей;
обрабатываемые данные содержат некоторые ошибки (помехи), обусловленные погрешностями измерений, воздействием неучтенных случайных факторов;
матрица результатов наблюдений является единственной информацией об изучаемом объекте, имеющейся в распоряжении перед началом исследования.
Функция f (x2, x3, …, xт), описывающая зависимость показателя от параметров, называется уравнением (функцией) регрессии. Термин "регрессия" (regression (лат.) - отступление, возврат к чему-либо) связан со спецификой одной из конкретных задач, решенных на стадии становления метода.
Решение задачи регрессионного анализа целесообразно разбить на несколько этапов:
предварительная обработка данных;
выбор вида уравнений регрессии;
вычисление коэффициентов уравнения регрессии;
проверка адекватности построенной функции результатам наблюдений.
Предварительная обработка включает стандартизацию матрицы данных, расчет коэффициентов корреляции, проверку их значимости и исключение из рассмотрения незначимых параметров.
Выбор вида уравнения регрессии Задача определения функциональной зависимости, наилучшим образом описывающей данные, связана с преодолением ряда принципиальных трудностей. В общем случае для стандартизованных данных функциональную зависимость показателя от параметров можно представить в виде
y = f (x1, x2, …, xm) + e
где f - заранее не известная функция, подлежащая определению;
e - ошибка аппроксимации данных.
Указанное уравнение принято называть выборочным уравнением регрессии. Это уравнение характеризует зависимость между вариацией показателя и вариациями факторов. А мера корреляции измеряет долю вариации показателя, которая связана с вариацией факторов. Иначе говоря, корреляцию показателя и факторов нельзя трактовать как связь их уровней, а регрессионный анализ не объясняет роли факторов в создании показателя.
Еще одна особенность касается оценки степени влияния каждого фактора на показатель. Регрессионное уравнение не обеспечивает оценку раздельного влияния каждого фактора на показатель, такая оценка возможна лишь в случае, когда все другие факторы не связаны с изучаемым. Если изучаемый фактор связан с другими, влияющими на показатель, то будет получена смешанная характеристика влияния фактора. Эта характеристика содержит как непосредственное влияние фактора, так и опосредованное влияние, оказанное через связь с другими факторами и их влиянием на показатель.
В регрессионное уравнение не рекомендуется включать факторы, слабо связанные с показателем, но тесно связанные с другими факторами. Не включают в уравнение и факторы, функционально связанные друг с другом (для них коэффициент корреляции равен 1). Включение таких факторов приводит к вырождению системы уравнений для оценок коэффициентов регрессии и к неопределенности решения.
Функция f должна подбираться так, чтобы ошибка e в некотором смысле была минимальна. В целях выбора функциональной связи заранее выдвигают гипотезу о том, к какому классу может принадлежать функция f, а затем подбирают "лучшую" функцию в этом классе. Выбранный класс функций должен обладать некоторой "гладкостью", т.е. "небольшие" изменения значений аргументов должны вызывать "небольшие" изменения значений функции.
Частным случаем, широко применяемым на практике, является полином первой степени или уравнение линейной регрессии
Для выбора вида функциональной зависимости можно рекомендовать следующий подход:
в пространстве параметров графически отображают точки со значениями показателя. При большом количестве параметров можно строить точки применительно к каждому из них, получая двумерные распределения значений;
по расположению точек и на основе анализа сущности взаимосвязи показателя и параметров объекта делают заключение о примерном виде регрессии или ее возможных вариантах;
после расчета параметров оценивают качество аппроксимации, т.е. оценивают степень близости расчетных и фактических значений;
если расчетные и фактические значения близки во всей области задания, то задачу регрессионного анализа можно считать решенной. В противном случае можно попытаться выбрать другой вид полинома или другую аналитическую функцию, например периодическую.
Вычисление коэффициентов уравнения регрессии
Систему уравнений на основе имеющихся данных однозначно решить невозможно, так как количество неизвестных всегда больше количества уравнений. Для преодоления этой проблемы нужны дополнительные допущения. Здравый смысл подсказывает: желательно выбрать коэффициенты полинома так, чтобы обеспечить минимум ошибки аппроксимации данных. Могут применяться различные меры для оценки ошибок аппроксимации. В качестве такой меры нашла широкое применение среднеквадратическая ошибка. На ее основе разработан специальный метод оценки коэффициентов уравнений регрессии - метод наименьших квадратов (МНК). Этот метод позволяет получить оценки максимального правдоподобия неизвестных коэффициентов уравнения регрессии при нормальном распределения вариант, но его можно применять и при любом другом распределении факторов.
В основе МНК лежат следующие положения:
значения величин ошибок и факторов независимы, а значит, и некоррелированы, т.е. предполагается, что механизмы порождения помехи не связаны с механизмом формирования значений факторов;
математическое ожидание ошибки e должно быть равно нулю (постоянная составляющая входит в коэффициент a0), иначе говоря, ошибка является центрированной величиной;
выборочная оценка дисперсии ошибки должна быть минимальна.
Если же линейная модель неточна или параметры измеряются неточно, то и в этом случае МНК позволяет найти такие значения коэффициентов, при которых линейная модель наилучшим образом описывает реальный объект в смысле выбранного критерия среднеквадратического отклонения.
Качество полученного уравнения регрессии оценивают по степени близости между результатами наблюдений за показателем и предсказанными по уравнению регрессии значениями в заданных точках пространства параметров. Если результаты близки, то задачу регрессионного анализа можно считать решенной. В противном случае следует изменить уравнение регрессии и повторить расчеты по оценке параметров.
При наличии нескольких показателей задача регрессионного анализа решается независимо для каждого из них.
Анализируя сущность уравнения регрессии, следует отметить следующие положения. Рассмотренный подход не обеспечивает раздельной (независимой) оценки коэффициентов - изменение значения одного коэффициента влечет изменение значений других. Полученные коэффициенты не следует рассматривать как вклад соответствующего параметра в значение показателя. Уравнение регрессии является всего лишь хорошим аналитическим описанием имеющихся данных, а не законом, описывающим взаимосвязи параметров и показателя. Это уравнение применяют для расчета значений показателя в заданном диапазоне изменения параметров. Оно ограниченно пригодно для расчета вне этого диапазона, т.е. его можно применять для решения задач интерполяции и в ограниченной степени для экстраполяции.
Главной причиной неточности прогноза является не столько неопределенность экстраполяции линии регрессии, сколько значительная вариация показателя за счет неучтенных в модели факторов. Ограничением возможности прогнозирования служит условие стабильности неучтенных в модели параметров и характера влияния учтенных факторов модели. Если резко меняется внешняя среда, то составленное уравнение регрессии потеряет свой смысл.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения параметра, является точечным. Вероятность реализации такого прогноза ничтожна мала. Целесообразно определить доверительный интервал прогноза. Для индивидуальных значений показателя интервал должен учитывать ошибки в положении линии регрессии и отклонения индивидуальных значений от этой линии .
ВЫВОД ИТОГОВ
| Регрессионная статистика | |
| Множественный R | 0,998364 |
| R-квадрат | 0,99673 |
| Нормированный R-квадрат | 0,996321 |
| Стандартная ошибка | 0,42405 |
| Наблюдения | 10 |
Сначала рассмотрим верхнюю часть расчетов, представленную в таблице 8.3а , - регрессионную статистику.
Величина R-квадрат , называемая также мерой определенности, характеризует качество полученной регрессионной прямой. Это качество выражается степенью соответствия между исходными данными и регрессионной моделью (расчетными данными). Мера определенности всегда находится в пределах интервала .
В большинстве случаев значение R-квадрат находится между этими значениями, называемыми экстремальными, т.е. между нулем и единицей.
Если значение R-квадрата близко к единице, это означает, что построенная модель объясняет почти всю изменчивость соответствующих переменных. И наоборот, значение R-квадрата , близкое к нулю, означает плохое качество построенной модели.
В нашем примере мера определенности равна 0,99673, что говорит об очень хорошей подгонке регрессионной прямой к исходным данным.
Множественный R - коэффициент множественной корреляции R - выражает степень зависимости независимых переменных (X) и зависимой переменной (Y).
Множественный R равен квадратному корню из коэффициента детерминации, эта величина принимает значения в интервале от нуля до единицы.
В простом линейном регрессионном анализе множественный R равен коэффициенту корреляции Пирсона. Действительно, множественный R в нашем случае равен коэффициенту корреляции Пирсона из предыдущего примера (0,998364).
| Коэффициенты | Стандартная ошибка | t-статистика | |
| Y-пересечение | 2,694545455 | 0,33176878 | 8,121757129 |
| Переменная X 1 | 2,305454545 | 0,04668634 | 49,38177965 |
| * Приведен усеченный вариант расчетов | |||
Теперь рассмотрим среднюю часть расчетов, представленную в таблице 8.3б . Здесь даны коэффициент регрессии b (2,305454545) и смещение по оси ординат, т.е. константа a (2,694545455).
Исходя из расчетов, можем записать уравнение регрессии таким образом:
Y= x*2,305454545+2,694545455
Направление связи между переменными определяется на основании знаков (отрицательный или положительный) коэффициентов регрессии (коэффициента b).
Если знак при коэффициенте регрессии - положительный, связь зависимой переменной с независимой будет положительной. В нашем случае знак коэффициента регрессии положительный, следовательно, связь также является положительной.
Если знак при коэффициенте регрессии - отрицательный, связь зависимой переменной с независимой является отрицательной (обратной).
В таблице 8.3в . представлены результаты вывода остатков . Для того чтобы эти результаты появились в отчете, необходимо при запуске инструмента "Регрессия" активировать чекбокс "Остатки".
ВЫВОД ОСТАТКА
| Наблюдение | Предсказанное Y | Остатки | Стандартные остатки |
|---|---|---|---|
| 1 | 9,610909091 | -0,610909091 | -1,528044662 |
| 2 | 7,305454545 | -0,305454545 | -0,764022331 |
| 3 | 11,91636364 | 0,083636364 | 0,209196591 |
| 4 | 14,22181818 | 0,778181818 | 1,946437843 |
| 5 | 16,52727273 | 0,472727273 | 1,182415512 |
| 6 | 18,83272727 | 0,167272727 | 0,418393181 |
| 7 | 21,13818182 | -0,138181818 | -0,34562915 |
| 8 | 23,44363636 | -0,043636364 | -0,109146047 |
| 9 | 25,74909091 | -0,149090909 | -0,372915662 |
| 10 | 28,05454545 | -0,254545455 | -0,636685276 |
При помощи этой части отчета мы можем видеть отклонения каждой точки от построенной линии регрессии. Наибольшее абсолютное значение
В своих работах, датированных ещё 1908 годом. Он описал его на примере работы агента, осуществляющего продажу недвижимости. В своих записях специалист по торговле домами вёл учёт широкого спектра исходных данных каждого конкретного строения. По результатам торгов определялось, какой фактор имел наибольшее влияние на цену сделки.
Анализ большого количества сделок дал интересные результаты. На конечную стоимость оказывали влияние множество факторов, иногда приводя к парадоксальным выводам и даже к явным «выбросам», когда дом с высоким изначальным потенциалом продавался по заниженному ценовому показателю.
Вторым примером применения подобного анализа приведена работа которому было доверено определение вознаграждения сотрудникам. Сложность задачи заключалась в том, что требовалась не раздача фиксированной суммы каждому, а строгое соответствие её величины конкретно выполненной работе. Появление множества задач, имеющих практически сходный вариант решения, потребовало более детального их изучения на математическом уровне.
В существенное место было отведено под раздел «регрессионный анализ», в нём объединились практические методы, используемые для исследования зависимостей, подпадающих под понятие регрессионных. Эти взаимосвязи наблюдаются между данными, полученными в ходе статистических исследований.
Среди множества решаемых задач основными ставит перед собой три цели: определение для уравнения регрессии общего вида; построение оценок параметров, являющихся неизвестными, которые входят в состав уравнения регрессии; проверка статистических регрессионных гипотез. В ходе изучения связи, возникающей между парой величин, полученных в результате экспериментальных наблюдений и составляющих ряд (множество) типа (x1, y1), ..., (xn, yn), опираются на положения теории регрессии и предполагают, что для одной величины Y наблюдается определённое вероятностное распределение, при том, что другое X остаётся фиксированным.
Результат Y зависит от значения переменной X, зависимость эта может определяться различными закономерностями, при этом на точность полученных результатов оказывает влияние характер наблюдений и цель анализа. Экспериментальная модель основывается на определённых допущениях, которые являются упрощёнными, но правдоподобными. Основным условием является то, что параметр X является величиной контролируемой. Его значения задаются до начала эксперимента.
Если в ходе эксперимента используется пара неконтролируемых величин XY, то регрессионный анализ осуществляется одним и тем же способом, но для интерпретации результатов, в ходе которой изучается связь исследуемых случайных величин, применяются методы Методы математической статистики не являются отвлеченной темой. Они находят себе применение в жизни в самых различных сферах деятельности человека.
В научной литературе для определения выше указанного метода нашёл широкое использование термин линейный регрессионный анализ. Для переменной X применяют термин регрессор или предиктор, а зависимые Y-переменные ещё называют критериальными. В данной терминологии отражается лишь математическая зависимость переменных, но никак не следственно-причинные отношения.
Регрессионный анализ служит наиболее распространённым методом, который используется в ходе обработки результатов самых различных наблюдений. Физические и биологические зависимости изучаются по средствам данного метода, он реализован и в экономике, и в технике. Масса других областей используют модели регрессионного анализа. Дисперсионный анализ, статистический анализ многомерный тесно сотрудничают с данным способом изучения.
При наличии корреляционной связи между факторными и результативными признаками врачам нередко приходится устанавливать, на какую величину может измениться значение одного признака при изменении другого на общепринятую или установленную самим исследователем единицу измерения.
Например, как изменится масса тела школьников 1-го класса (девочек или мальчиков), если рост их увеличится на 1 см. В этих целях применяется метод регрессионного анализа.
Наиболее часто метод регрессионного анализа применяется для разработки нормативных шкал и стандартов физического развития.
- Определение регрессии
. Регрессия - функция, позволяющая по средней величине одного признака определить
среднюю величину другого признака, корреляционно связанного с первым.
С этой целью применяется коэффициент регрессии и целый ряд других параметров. Например, можно рассчитать число простудных заболеваний в среднем при определенных значениях среднемесячной температуры воздуха в осенне-зимний период.
- Определение коэффициента регрессии . Коэффициент регрессии - абсолютная величина, на которую в среднем изменяется величина одного признака при изменении другого связанного с ним признака на установленную единицу измерения.
- Формула коэффициента регрессии
. R у/х = r ху x (σ у / σ x)
где R у/х - коэффициент регрессии;
r ху - коэффициент корреляции между признаками х и у;
(σ у и σ x) - среднеквадратические отклонения признаков x и у.В нашем примере ;
σ х = 4,6 (среднеквадратическое отклонение температуры воздуха в осенне-зимний период;
σ у = 8,65 (среднеквадратическое отклонение числа инфекционно-простудных заболеваний).
Таким образом, R у/х - коэффициент регрессии.
R у/х = -0,96 х (4,6 / 8,65) = 1,8, т.е. при снижении среднемесячной температуры воздуха (x) на 1 градус среднее число инфекционно-простудных заболеваний (у) в осенне-зимний период будет изменяться на 1,8 случаев. - Уравнение регрессии
. у = М у + R y/x (х - М x)
где у - средняя величина признака, которую следует определять при изменении средней величины другого признака (х);
х - известная средняя величина другого признака;
R y/x - коэффициент регрессии;
М х, М у - известные средние величины признаков x и у.Например, среднее число инфекционно-простудных заболеваний (у) можно определить без специальных измерений при любом среднем значении среднемесячной температуры воздуха (х). Так, если х = - 9°, R у/х = 1,8 заболеваний, М х = -7°, М у = 20 заболеваний, то у = 20 + 1,8 х (9-7) = 20 + 3,6 = 23,6 заболеваний.
Данное уравнение применяется в случае прямолинейной связи между двумя признаками (х и у). - Назначение уравнения регрессии . Уравнение регрессии используется для построения линии регрессии. Последняя позволяет без специальных измерений определить любую среднюю величину (у) одного признака, если меняется величина (х) другого признака. По этим данным строится график - линия регрессии , по которой можно определить среднее число простудных заболеваний при любом значении среднемесячной температуры в пределах между расчетными значениями числа простудных заболеваний.
- Сигма регрессии (формула)
.
где σ Rу/х - сигма (среднеквадратическое отклонение) регрессии;
σ у - среднеквадратическое отклонение признака у;
r ху - коэффициент корреляции между признаками х и у.Так, если σ у - среднеквадратическое отклонение числа простудных заболеваний = 8,65; r ху - коэффициент корреляции между числом простудных заболеваний (у) и среднемесячной температурой воздуха в осенне-зимний период (х) равен - 0,96, то

- Назначение сигмы регрессии
. Дает характеристику меры разнообразия результативного признака (у).
Например, характеризует разнообразие числа простудных заболеваний при определенном значении среднемесячной температуры воздуха в осеннне-зимний период. Так, среднее число простудных заболеваний при температуре воздуха х 1 = -6° может колебаться в пределах от 15,78 заболеваний до 20,62 заболеваний.
При х 2 = -9° среднее число простудных заболеваний может колебаться в пределах от 21,18 заболеваний до 26,02 заболеваний и т.д.Сигма регрессии используется при построении шкалы регрессии, которая отражает отклонение величин результативного признака от среднего его значения, отложенного на линии регрессии.
- Данные, необходимые для расчета и графического изображения шкалы регрессии
- коэффициент регрессии - R у/х;
- уравнение регрессии - у = М у + R у/х (х-М x);
- сигма регрессии - σ Rx/y
- Последовательность расчетов и графического изображения шкалы регрессии
.
- определить коэффициент регрессии по формуле (см. п. 3). Например, следует определить, насколько в среднем будет меняться масса тела (в определенном возрасте в зависимости от пола), если средний рост изменится на 1 см.
- по формуле уравнения регрессии (см п. 4) определить, какой будет в среднем, например, масса тела (у, у 2 ,
у 3 ...)* для определеного значения роста (х, х 2 , х 3 ...).
________________
* Величину "у" следует рассчитывать не менее чем для трех известных значений "х".При этом средние значения массы тела и роста (М х, и М у) для определенного возраста и пола известны
- вычислить сигму регрессии, зная соответствующие величины σ у и r ху и подставляя их значения в формулу (см. п. 6).
- на основании известных значений х 1 , х 2 , х 3 и соответствующих им средних значений
у 1 , у 2 у 3 , а также наименьших (у - σ rу/х)и наибольших (у + σ rу/х)
значений (у) построить шкалу регрессии.
Для графического изображения шкалы регрессии на графике сначала отмечаются значения х, х 2 , х 3 (ось ординат), т.е. строится линия регрессии, например зависимости массы тела (у) от роста (х).
Затем в соответствующих точках у 1 , y 2 , y 3 отмечаются числовые значения сигмы регрессии, т.е. на графике находят наименьшее и наибольшее значения у 1 , y 2 , y 3 .
- Практическое использование шкалы регрессии
. Разрабатываются нормативные шкалы и стандарты, в частности по
физическому развитию. По стандартной шкале можно дать индивидуальную оценку развития детей.
При этом физическое развитие оценивается как гармоничное, если, например, при определенном росте масса тела ребенка находится в
пределах одной сигмы регрессии к средней расчетной единице массы тела - (у) для данного роста (x)
(у ± 1 σ Ry/x).
Физическое развитие считается дисгармоничным по массе тела, если масса тела ребенка для определенного роста находится в пределах второй сигмы регрессии: (у ± 2 σ Ry/x)
Физическое развитие будет резко дисгармоничным как за счет избыточной, так и за счет недостаточной массы тела, если масса тела для определенного роста находится в пределах третьей сигмы регрессии (у ± 3 σ Ry/x).
По результатам статистического исследования физического развития мальчиков 5 лет известно, что их средний рост (х) равен 109 см, а средняя масса тела (у) равна 19 кг. Коэффициент корреляции между ростом и массой тела составляет +0,9, средние квадратические отклонения представлены в таблице.
Требуется:
- рассчитать коэффициент регрессии;
- по уравнению регрессии определить, какой будет ожидаемая масса тела мальчиков 5 лет при росте, равном х1 = 100 см, х2 = 110 см, х3= 120 см;
- рассчитать сигму регрессии, построить шкалу регрессии, результаты ее решения представить графически;
- сделать соответствующие выводы.
Условие задачи и результаты ее решения представлены в сводной таблице.
Таблица 1
| Условия задачи | Pезультаты решения задачи | ||||||||
| уравнение регрессии | сигма регрессии | шкала регрессии (ожидаемая масса тела (в кг)) | |||||||
| М | σ | r ху | R у/x | х | У | σ R x/y | y - σ Rу/х | y + σ Rу/х | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Рост (х) | 109 см | ± 4,4см | +0,9 | 0,16 | 100см | 17,56 кг | ± 0,35 кг | 17,21 кг | 17,91 кг |
| Масса тела (y) | 19 кг | ± 0,8 кг | 110 см | 19,16 кг | 18,81 кг | 19,51 кг | |||
| 120 см | 20,76 кг | 20,41 кг | 21,11 кг | ||||||
Решение .
Вывод.
Таким образом, шкала регрессии в пределах расчетных величин массы тела позволяет определить ее при любом другом
значении роста или оценить индивидуальное развитие ребенка. Для этого следует восстановить перпендикуляр к линии регрессии.
- Власов В.В. Эпидемиология. - М.: ГЭОТАР-МЕД, 2004. - 464 с.
- Лисицын Ю.П. Общественное здоровье и здравоохранение. Учебник для вузов. - М.: ГЭОТАР-МЕД, 2007. - 512 с.
- Медик В.А., Юрьев В.К. Курс лекций по общественному здоровью и здравоохранению: Часть 1. Общественное здоровье. - М.: Медицина, 2003. - 368 с.
- Миняев В.А., Вишняков Н.И. и др. Социальная медицина и организация здравоохранения (Руководство в 2 томах). - СПб, 1998. -528 с.
- Кучеренко В.З., Агарков Н.М. и др.Социальная гигиена и организация здравоохранения (Учебное пособие) - Москва, 2000. - 432 с.
- С. Гланц. Медико-биологическая статистика. Пер с англ. - М., Практика, 1998. - 459 с.